Compression Algorithm
DELTA
Mainly used for timestamp, integer and unsigned integer.
Principle
First, the difference is made, that is, the first data is unchanged, other data are transformed into delta with the previous data, and all numbers are processed byzigzag, i64 is mapped to u64, specifically to zero, negative numbers are mapped to odd numbers, such as [0, 1, 2] after zigzag processing to [0, 1,2] and maximum convention numbers are calculated. Then judge that if all deltas are the same, use the cruise path code directly, that is, only the first value, delta, and the number of data. Otherwise, all delta values are divided into maximum convention numbers (maximum convention numbers are encoded into data), and then encoded using Simple 8b.

Simple 8b is a compression algorithm that encapsulates multiple integers to a 64-bit integer, the first four-bit as selector to specify the number and validity of integers stored in the remaining 60 bits, and the latter 60 bits are used to store multiple integers. In addition, when delta is larger than the maximum range of Simple 8b energy encoding (more than 1<60-1, generally not) does not compress and stores arrays directly.
Applicability
In some time-consuming data, assuming that data is collected every five seconds, the time stamp is 5, that all timestamps can be restored through only three numbers, with extremely high compression, while some delta does not guarantee consistent scenarios, i.e., where using Simple 8b, are more suitable for smaller, floating data.
In the absence of specifying compression algorithms, we use this compression algorithm for timemarks, integer and unsigned integers, and the compression rate is higher.
GORILLA
Mainly used for floating point type.
Principle
The principle of Gorilla is similar to the difference, the difference is that the difference is the difference between two data, and gorilla is different or different. The first data is not processed at the time of coding, and if the previous data is different from the previous data, if the difference or value is 0, repeat it with the previous data, write a patch to represent repetition, and, if not zero, calculate the first zero and back derivative zeros of the heterogeneous or value delta. If the number is the same, only the intermediate valid bit is encoded. If the number is different, the first 0.5 bits are derived, the back 0. 5 bits are written, and then the intermediate valid bit is written.
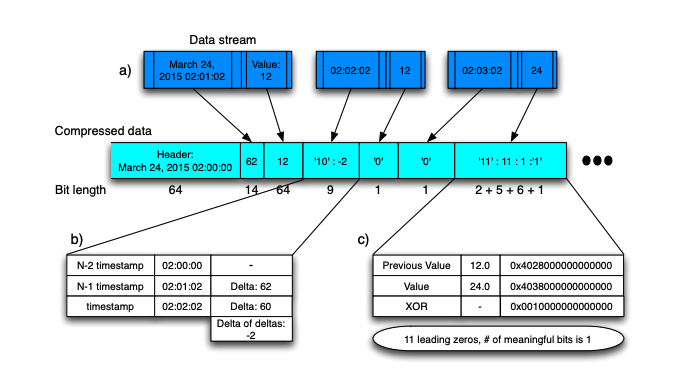
Applicability
As compared with delta type, it is also suitable for time-order data scenarios, and we may collect data in different locations, but the toponymic-related information collected at the same location is generally consistent, in which the compression rate is higher than that of compression efficiency.
In the absence of specifying compression algorithms, we specify this compression algorithm for floating point type by default.
QUANTILE
Mainly used for timestamps, integers, unsigned integers and floating points.
Principle
Qantile supports multiple levels of compression, and CosDB currently uses the default compression level.
Each data is described by Huffman coding and offset, and the offset specifies the exact location of the range of the data by the Huffman code corresponding to the range of the data. For each block compression, the difference processing is first carried out, the data after the difference is replaced by the current data, then the current array is divided into multiple blocks at an interval of 128, each block determines a range and associated metadata, while calculating the maximum number of conventions per block, optimizes the number of conventions as appropriate, and merges some adjacent blocks, then determines its Huffman encoding based on the weight of each block in the data, and finally encodes the data using them.
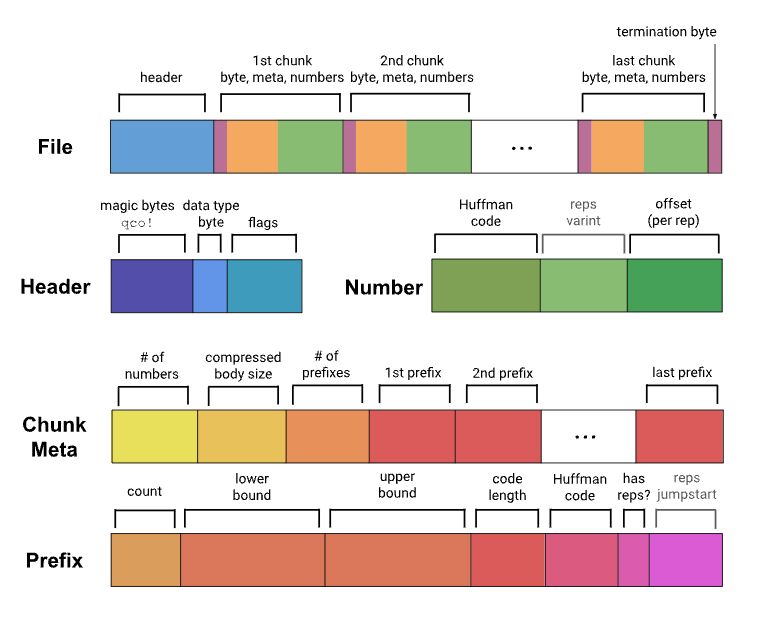
Applicability
Compared with the delta algorithm and the gorilla algorithm, because the difference algorithm is also used, it is roughly the same in the selection of applicable data.
The longitudinal axis of the image is the compression ratio, the time is only relative.
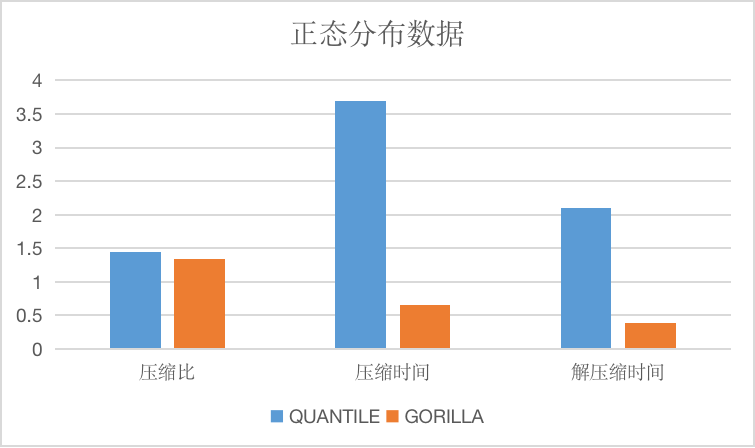
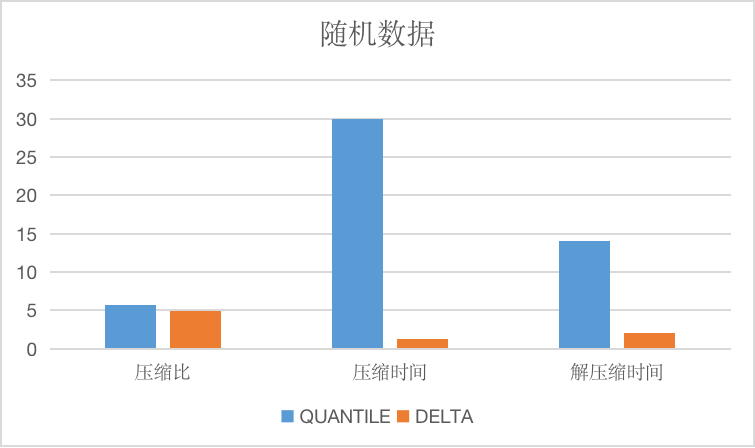
BITPACK
Mainly used for Boolean types.
Principle
The size of a bool-type data is a byte, and for the information that bool represents, it's only one bit to represent so that we can assemble eight bool-type data into one byte.
Applicability
No matter what data, we can ensure a compression ratio of nearly eight times that we specify this compression algorithm for the Boolean type by default without specifying the compression algorithm.
String Compression Algorithm
The string compression algorithm currently supported is compressed, such as below.
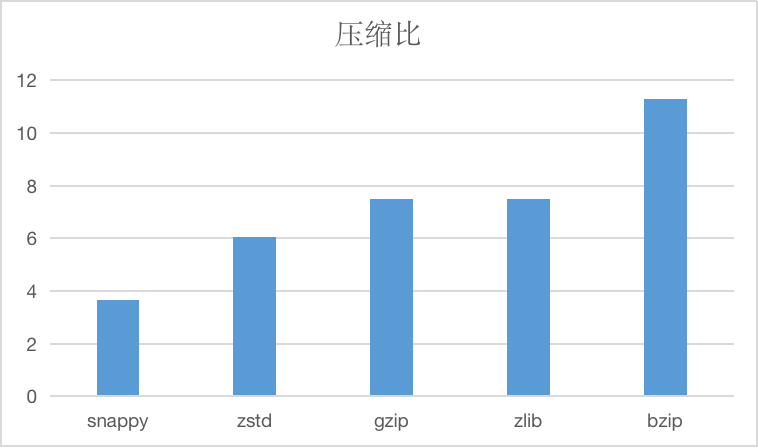
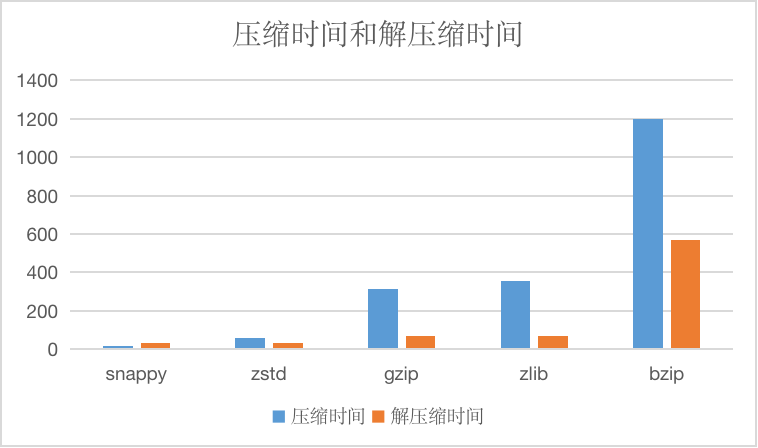
And compressed time and decompression time, units are us.
SNAPPY
Snappy algorithms are not designed to minimize compression or are not designed to be compatible with any other compression library. Instead, its goal is to be very high compression efficiency and reasonable compression rates, so it is recommended to use snappy more efficiently.
In the absence of specifying a string compression algorithm, we specify this compression algorithm by default.
ZSTD
Zstd supports multiple compression levels, and CnosDB currently uses the default compression level.
Zstd, known as Zstand, is a fast compression algorithm that provides high compression ratio, and Zstt uses a finite state entropy encoder. A very powerful compromise scheme for compression speed/compression rate is provided.
GZIP/ZLIB
Gzip is similar to zlib. For files to be compressed, a variant of the LZ77 algorithm is first used to compress the results by using Huffman coding, with high compression rate but also time-consuming. Both algorithms are widely used and have similar performances and can be selected according to the situation.
BZIP
Compared with several other algorithms, the compression rate is higher, but the compression efficiency is lower, which can be used for scenarios that require extreme compression rate, in general less recommended.
Lossy Compression Algorithm
Only available in the Enterprise Edition.
SDT Compression Algorithm
Mainly used for integer, unsigned integer, floating point type.
The Revolving Door Trend (SDT) is an online lossy data compression algorithm traditionally used in Supervisory Control and Data Acquisition (SCADA) systems designed to store historical data of Procedural information Systems (PIMs). SDT has low computational complexity and uses a linear trend to represent a certain amount of data. Its most important parameter is the compression deviation, which represents the maximum difference between the current sample and the current linear trend used to represent the previously collected data. The idea is to look at the compression offset coverage between the current data point and the previous retained data point to decide which data to choose. If the offset coverage area can cover all points in between, the data point is not retained. If a number of points fall outside the compression offset coverage area, it is retained when The previous point of the previous data point and take the latest retained data point as the new starting point.
Algorithm parameters
Deviation: A positive floating point number It represents the maximum difference between the current sample and the current linear trend.
Dead zone compression algorithm
Mainly used for integer, unsigned integer, floating point type.
The principle of the dead zone compression algorithm is: for the time series variable data, the variable change limit (namely dead zone, or threshold) is defined. If the deviation between the current data and the last stored data exceeds the specified dead zone, the current data will be saved, otherwise the current data will be discarded. This algorithm only needs to compare the continuous data from the time series with the previous saved data to determine whether the data needs to be saved. Because of this, it is easy to understand and implement, and most real-time databases with lossy compression provide this compression method.
Algorithm parameters
Deviation: A positive floating point number The absolute or relative value of the allowable deviation when using the algorithm, based on the last saved number. It determines the compression rate of the algorithm and the accuracy of the compressed data.