存储引擎
TSKV 索引与数据存储
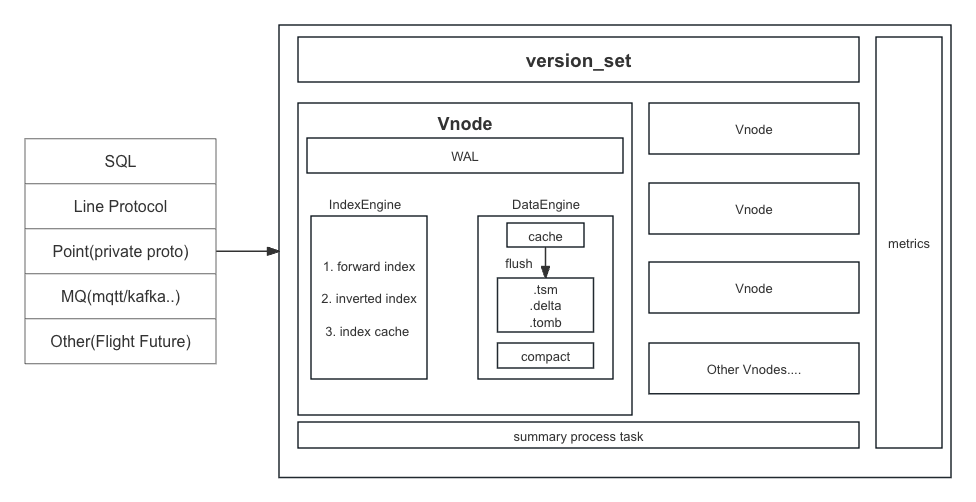
tskv 主要承担数据和索引的存储,对 Node 节点上所有 Vnode 进行管理, 每个 Vnode 负责某个 Database 里的部分数据。在 Vnode 中主要有 3 个模块组成 WAL,IndexEngine 和 DataEngine。
Index Engine
用来存储时序数据的索引通常来说是读多写少的模型,主要能够进行快速索引和基于 tagkey 进行条件过滤,过滤出合适的 series。
主要功能有:
- 存储正排索引。
- 存储倒排索引。
- 缓存索引数据。
常用查询语句:
SELECT xxx from table where tag1= value1 && tag2=value2 [and time > aaa and time < bbb] [group by\order by\limit ....]
索引的设计主要针对 where 过滤条件;用于降低数据的搜索规模,加快数据的查询效率。
支持以下几种过滤条件:
- 等于、不等于;如:tag=value,tag!=value
- 大于、小于;如:tag < value
- 前缀匹配;如:tag=aaa_*
- 正则表达式;如:tag=aaa*bbb
数据写入的时进行索引的构建。在时序数据库中多是对每个 tag 进行索引,多个 tag 所对应的 value 组合为一个 series key。
虽然时序数据库是写多读少,但是写入数据时对索引的使用更多是读取而不是构建。时序数据库多是对同一个 series 不同时间点采样写入,所以每个 series 的索引信息只在第一次写入时需要构建,后面写入时判断 series 存在(读操作)就不再进行索引构建。
索引数据
- SeriesID:每个 Vnode 有一个从0开始的自增变量 incr_id,当某个 SeriesKey 第一次写入时,incr_id 自增加一,incr_id 的值代表这个 series 的 SeriesID。
- SeriesKey:由表名和 tag key-value 对组成。
索引数据结构
- HashMap<SeriesID, SeriesKey>:用于根据 SeriesID 获取 SeriesKey。
- HashMap<SeriesKeyHash, SeriesID>: SeriesKeyHash 为 SeriesKey 的 hash 值,通过 SeriesKeyHash 获取 SeriesID。主要用于根据 SeriesKey 获取 SeriesID。
- HashMap<TableName, HashMap<TagKey, BtreeMap<TagValue, RoaringBitmap\<SeriesID>>>>: 倒排索引,根据给定的 TableName,以及 TagKey 和 TagValue 获取所有的 SeriesID。
索引数据与索引数据结构均会在写输入时根据写入的数据进行构建。
Data Engine
每个 DataEngine 为一个数据存储的 Node,每个 Node 上的数据存储在多个 Vnode 上,每个 Vnode 负责某个 Database 里的部分数据。在有备份的情况下,分布在多个 Node 上的互为备份 Vnode 之间通过 Raft 协议保持数据一致性。
每个 Vnode 为一个 LSM Tree,用于存储时序数据,同时每个 Vnode 又作为一个 Raft 节点。 所以在设计上每个 Vnode 主要由以下模块构成
WAL 模块
WAL 模块主要有两个功能
- 作为 LSM Tree 的 Write Ahead Log 模块,用于持久化数据。
- 作为 Raft 协议的 Raft Entry Log 模块,用于持久化 Raft 协议的日志。
在写入数据时,先将数据写入 WAL,然后再写入 VnodeState 的内存 cache 中,当 Node 宕机时,可以通过 WAL 恢复内存数据,以及 Raft 的状态。
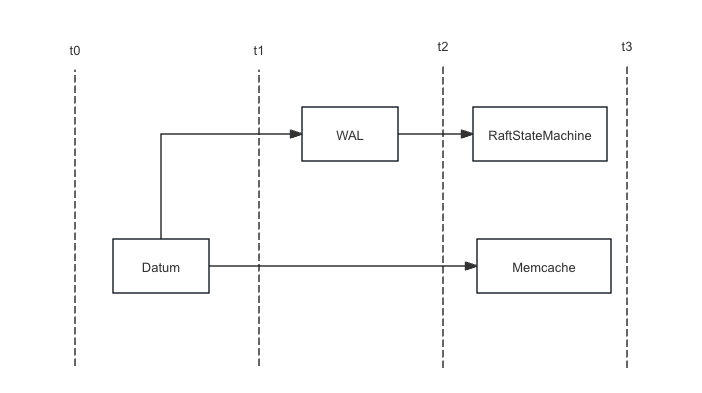
VnodeState 模块
VnodeState 模块是 LSM Tree 的内存 cache,还保存了 LSM Tree 在磁盘上的元数据信息,如 LSM Tree 磁盘层级,TSM文件位置,TSMReader 的缓存等。同时也是 Raft 协议状态机实际执行的地方,当 Raft 协议的日志被提交时,会在 VnodeState 上执行对应的操作。
Summary 模块
Summary 是 TSM 文件版本变更产生的元数据文件,可以理解为是 VnodeState 的 LSM Tree 元数据。用于宕机时恢复 VnodeState 中与 LSM Tree有关的信息。 每当文件版本变更时,会产生版本变更元信息
version_edit,存储在 summary 文件里。node 节点长时间运行会产生较大的 summary 文件,我们会定期将 summary 文件进行整合。减少宕机恢复的时间。TSM 模块
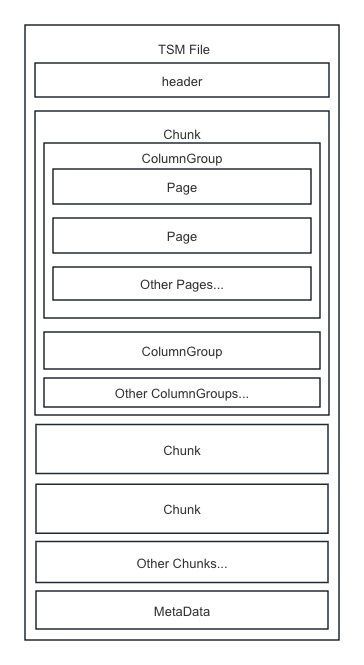
TSM 模块主要是对 TSM 文件的设计。每个 TSM 文件包含了多个 Chunk, 为了保证读取时不会太放大,每个 Chunk 按行数分了多个 ColumnGroup, 每个 ClomunGroup 包含了多个 Page, Page为最小的读取单元,存储了一列的部分数据。TSM 文件的读取是按照 Chunk -> ColumnGroup -> Page 的顺序进行的。文件末尾存储了文件的元信息,如文件的版本号,文件的大小,和当前文件数据的一些索引信息等。
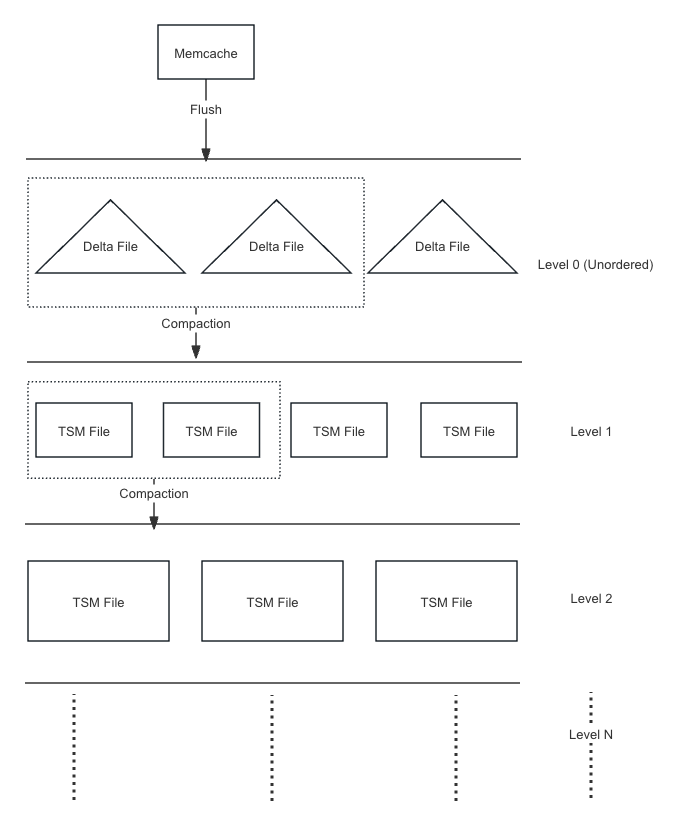
Compaction 模块
Flush
当 VnodeState 内存达到配置文件指定的阈值时,会触发 flush 操作,将内存中的数据打包为一个 flush request,发送到处理 flush 请求的线程中,写入到 TSM 文件。同时会生成对应的
version_edit,存储在 summary 文件中。Flush 过程将内存的 Memcache 按 series 切分,转为 DataBlock,将 DataBlock 编码转为 Chunk,再将 Chunk 写入 TSM 文件。
compaction
每隔一段时间(时间跨度配置在 Config 文件中),以及 Flush 请求结束时,会开始检查是否需要进行 compaction。当层级文件数目过多时,将同一层级的多个 TSM 文件进行合并,生成一个新的 TSM 文件,存储到下一个层级中。
compaction 的目的有:
- 把小的 tsm 文件进行聚合生成较大的 tsm 文件。
- 清理已过期或被标记删除的文件。
- 减小读放大,维护 VnodeState 中与层级有关的元数据。