压缩算法
时序数据规模很大,且可能存在大量冗余,因而在时序数据库中经常使用压缩方法来节约存储空间和查询执行时的I/O代价,下面将讨论CnosDB中使用的压缩技术。
DELTA
主要用于时间戳,整型以及无符号整型。
原理
首先进行差分,即第一个数据不变,其他数据转化为与上一个数据的delta,再将所有数字进行zigzag处理,即将i64映射到u64,具体为0映射到0,负数映射到奇数,正数映射到偶数,例如[0,-1,1,-2]经过zigzag处理后变为[0,1,2,3],并计算出最大公约数。之后判断一下如果所有的delta都相同,就直接使用游程编码,即只需要记录第一个值,delta和数据的数量。否则就将所有的delta值除以最大公约数(最大公约数也会编码进数据),然后使用simple8b进行编码。

simple8b是一种将多个整数打包到一个64位整数的压缩算法,前4位作为selector,用于指定剩余60位中储存的整数的个数和有效位长度,后60位用于储存多个整数。另外当delta的大小超过simple8b能编码的最大范围(超过1<<60 - 1,一般情况下不会出现)则不进行压缩,直接储存数组。
适用情况
在一些定时采集的数据,假设每5秒采集一次数据,时间戳的delta为5,通过游程编码仅仅通过三个数字就可以复原所有的时间戳,压缩比极高,而一些delta不能保证一致的场景,即在使用simple8b的情况下,更适用于范围较小的,浮动较小的数据。
在不指定压缩算法的情况下,我们默认为时间戳,整型和无符号整型使用这种压缩算法,压缩率与压缩效率都比较高。
GORILLA
主要用于浮点型。
原理
gorilla的原理与差分类似,区别在于差分是两个数据的差,gorilla则是异或。编码时第一个数据不进行处理,计算后一个的数据与前一个数据的异或,如果异或值为0,则表示与上一个数据重复,只存储一位零。如果不为零,则计算异或值的前导零和后导零个数,如果个数相同,则存储前缀10加有效位数据。如果个数不同,则存储前缀11加5位的前导零数量和6位的后导零数量,然后存储有效位数据。
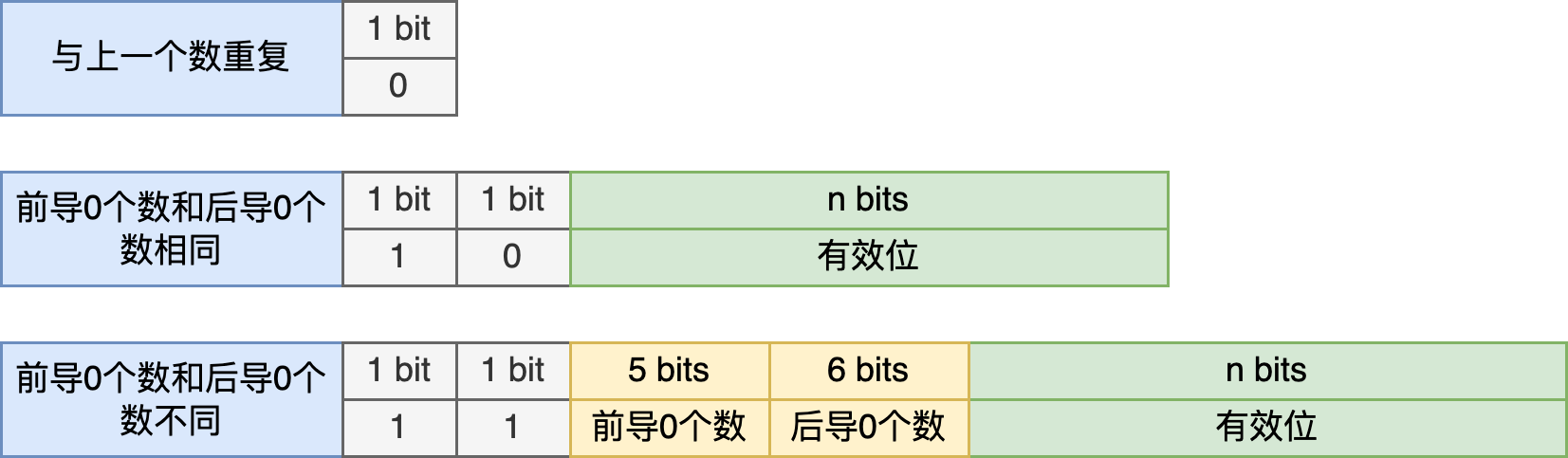
论文中给出的示例:
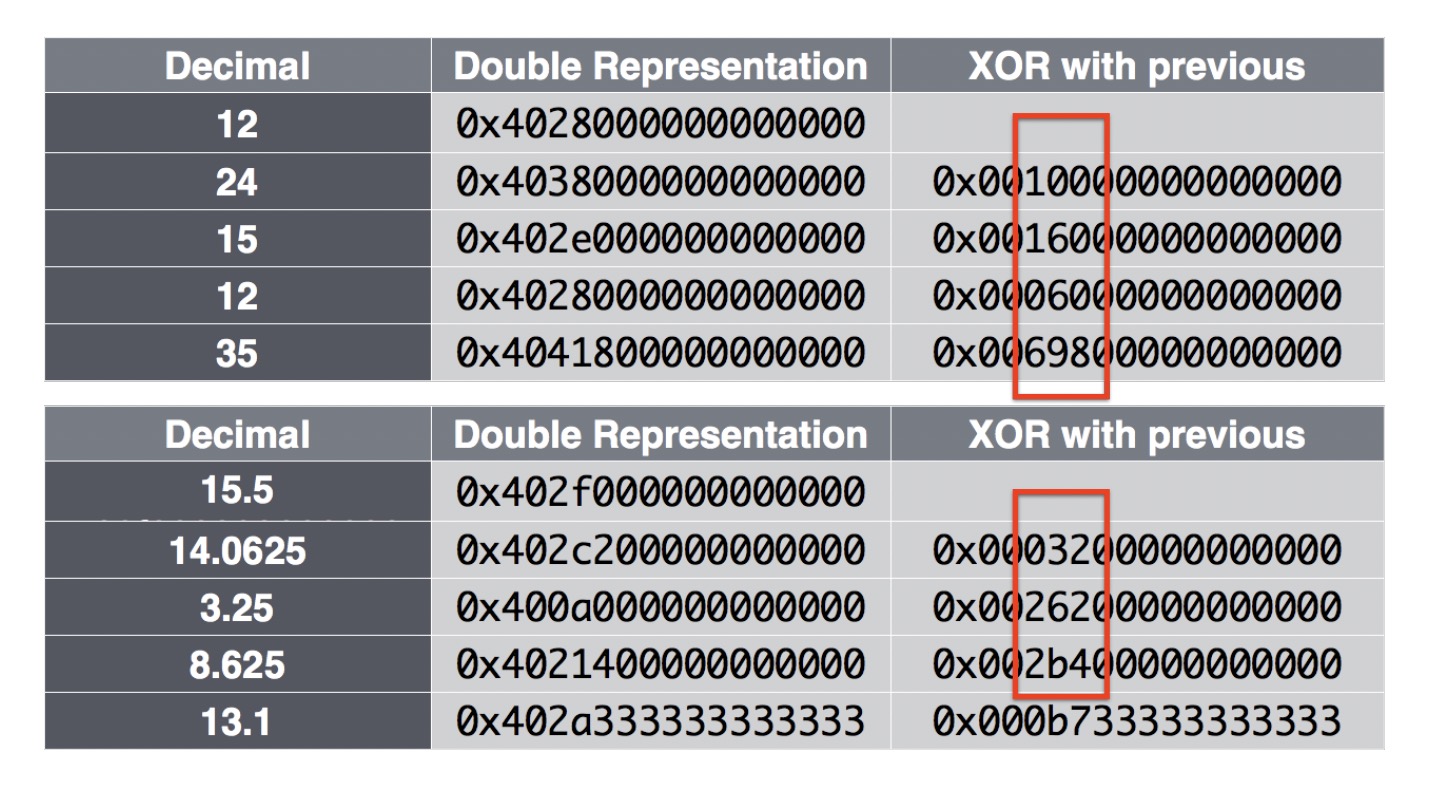
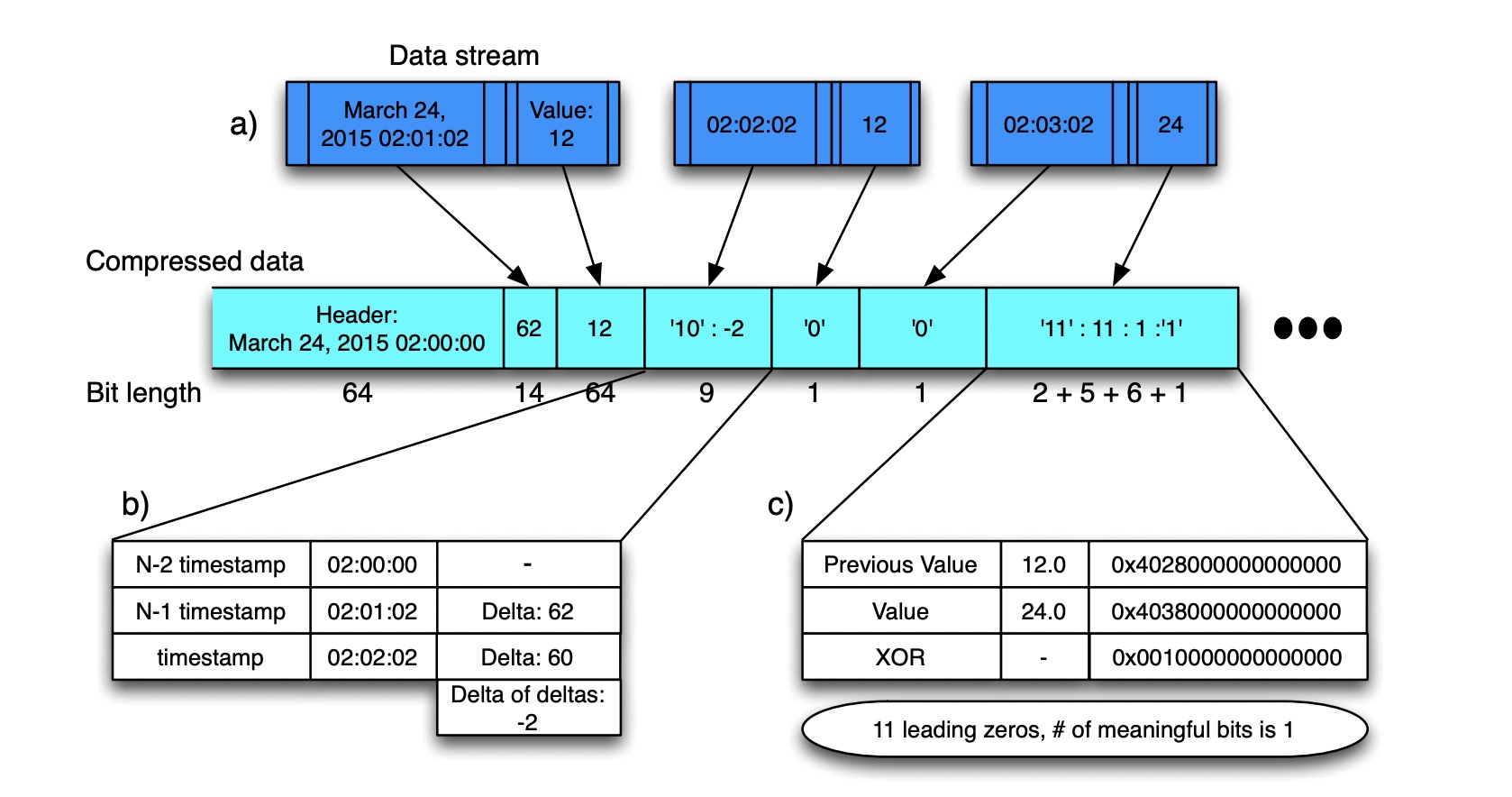
适用情况
与delta类型,同样比较适用于时序数据场景下,我们可能在不同地点采集数据,但同一地点采集的数据一般会有一定的平稳性,在这种场景下,压缩率与压缩效率都比较高。
在不指定压缩算法的情况下,我们默认为浮点型指定这种压缩算法。
Pco
主要用于时间戳,整型,无符号整型以及浮点数。
原理
Pco通过tANS算法对原始数据进行熵编码。tANS算法是一种现代的熵编码技术,它是ANS(Asymmetric numeral systems)的一种特定形式。tANS使用一个有限状态机,其中每个状态都对应于编码的可能结果。状态转换取决于待编码的符号,这使得它可以根据符号的概率分布进行调整。与传统的霍夫曼编码相比,tANS在处理符号概率分布不均匀的情况下可以提供更高的压缩率。tANS的具体原理可以参考这篇文章:Streaming Asymmetric Numeral System Explained。Pco的存储格式可以参考这篇文档:Pco-Format。
适用情况
由于Pco算法采用了更复杂的编码方式,导致压缩效率比较低,相对地,压缩率则优于delta与gorilla算法,下面是各种算法对测试数据集进行压缩的效果(对不同数据集的压缩效果可能不同)。
500M浮点数
| 压缩比 | 压缩时间 | 解压缩时间 | |
|---|---|---|---|
Gorilla | 4.50 | 13.652 µs | 70.830 ns |
Pco | 32.97 | 1.7491 s | 9.0485 ms |
500M整数
| 压缩比 | 压缩时间 | 解压缩时间 | |
|---|---|---|---|
Delta | 13.28 | 2.8366 ms | 58.428 µs |
Pco | 35.04 | 936.65 ms | 546.99 µs |
BITPACK
主要用于布尔类型。
原理
一个bool类型的数据的大小是一个字节,而对于bool所表示的信息,其实只需要1位就可以表示,这样我们可以将8个bool类型的数据组装成1个字节的数据。
适用情况
无论任何数据,都可以保证接近8倍的压缩比,在不指定压缩算法的情况下,我们默认为布尔类型指定这种压缩算法。
字符串压缩算法
目前支持的字符串压缩算法压缩比如下:
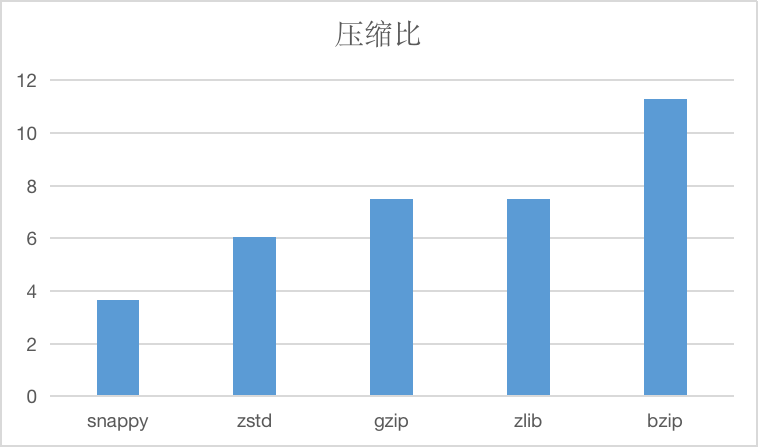
以及压缩时间和解压缩时间,单位为us
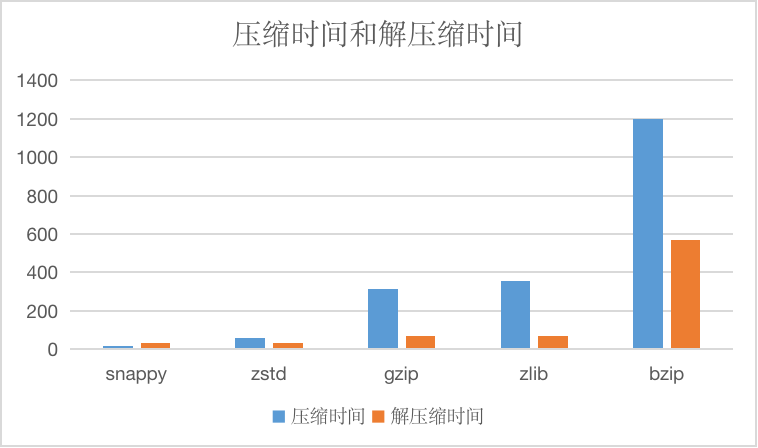
SNAPPY
snappy算法不旨在最大程度地压缩,也不旨在与任何其他压缩库兼容。相反,它的目标是非常高的压缩效率和合理的压缩率,所以在更加需要效率的情况下推荐使用snappy。
在不指定字符串压缩算法的情况下,我们默认指定这种压缩算法。
ZSTD
zstd支持多种压缩等级,CnosDB 目前采用默认的压缩等级。
Zstd 全称叫 Zstandard,是一个提供高压缩比的快速压缩算法,Zstd 采用了有限状态熵编码器。提供了非常强大的压缩速度/压缩率的折中方案。
GZIP/ZLIB
gzip与zlib比较相似,对于要压缩的文件,首先使用LZ77算法的一个变种进行压缩,对得到的结果再使用Huffman编码的方法进行压缩,压缩率很高,但同样比较耗时。这两种算法使用均比较广泛,性能相似,可以根据情况选择。
BZIP
与其他几种算法比较,压缩率更高,但是压缩效率也更低,可以用于需要极致压缩率的场景,一般情况下不太推荐使用。
有损压缩算法
仅企业版支持
SDT压缩算法
主要用于整型,无符号整型,浮点型。
旋转门趋势(SDT)是一种在线有损数据压缩算法,传统上用于监控和数据采集(SCADA)系统,旨在存储过程信息系统(PIMs)的历史数据。 SDT计算复杂度低,使用线性趋势来表示一定数量的数据。它最重要的参数是压缩偏差(deviation),它表示当前样本与用于表示先前收集的数据的当前线性趋势之间的最大差异。 其原理是通过 查看当前数据点与前一个被保留的数据点所构成的 压缩偏移覆盖区来决定数据的取舍。如果偏移覆盖区可以覆盖两者之间的所有点,则不保留该数据点;如果有数据点落在压缩偏移覆盖区之外,则保留当 前数据点的前一个点,并以最新保留的数据点作为新的起点。
算法参数
Deviation:正浮点数。它表示当前样本与当前线性趋势之间的最大差值。
死区压缩算法
主要用于整型,无符号整型,浮点型。
死区压缩算法的原理是: 对于时间序列的变量数据,规定好变量的变化限值(即死区,或称为阈值),若 当前数据与上一个保存的数据的偏差超过了规定的死区,那么就保存当前数据,否则丢弃。这 种算法对来自时间序列的连续数据,仅需与前一个保存的数据进行比较即可确定本数据是否需要保存,因 此易于理解和实现,大部分采用有损压缩的实时数据库都提供了这种压缩方式。
算法参数
Deviation: 正浮点数。使用该算法时允许偏差的绝对值或相对值,以最后一个已保存的数为基准。它决定了算法的压缩率,以及压缩后数据的精确度。