整体架构
CnosDB 2.0 采用 Rust 语言开发,凭借其卓越的安全性、高性能以及强大的社区支持,为用户提供了一款出色的时序数据库,构建了一整套完整的 DBaaS 解决方案。
主要特点如下:
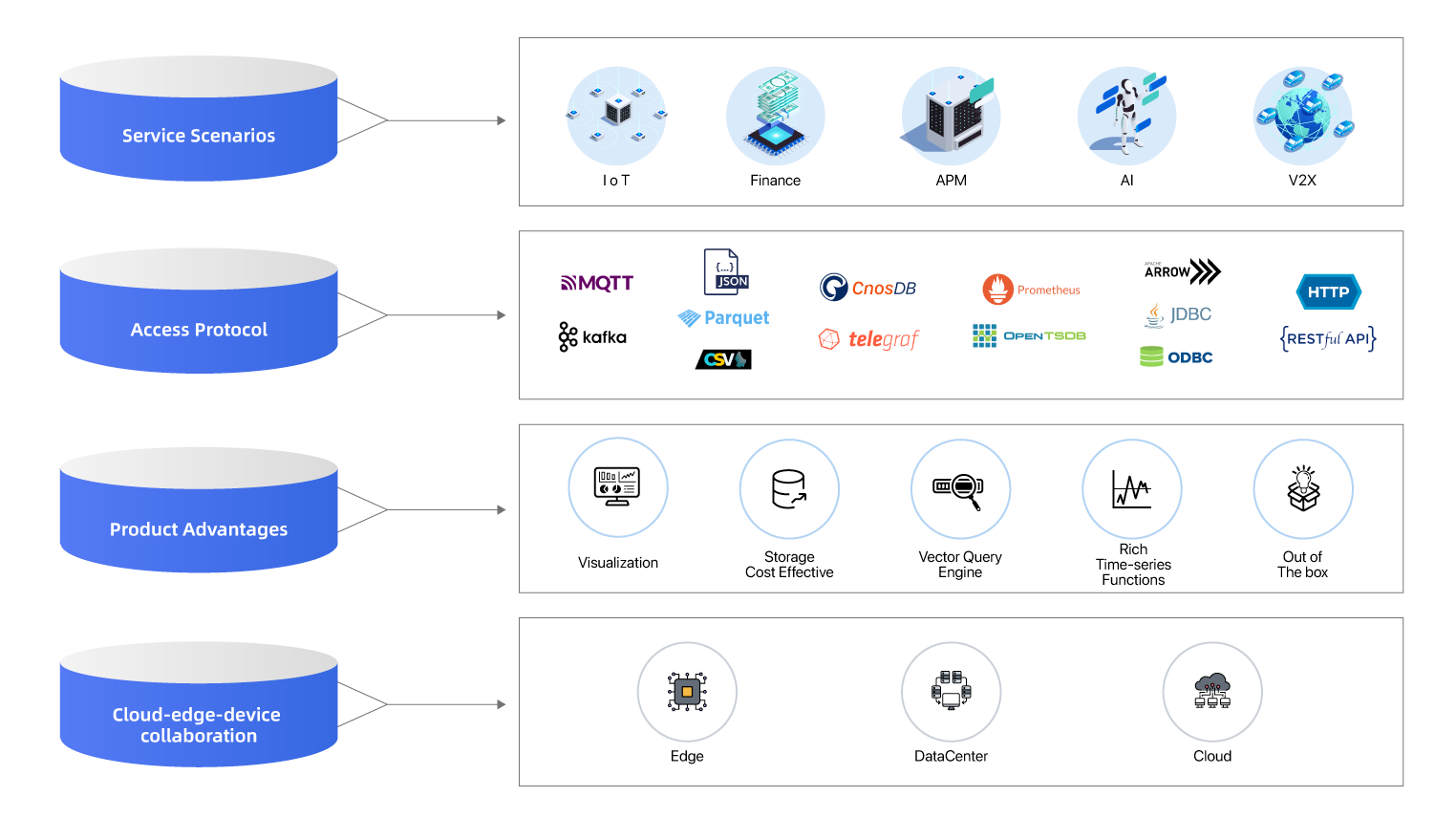
扩展性:理论上支持的时间序列无上限,彻底解决时间序列膨胀问题,支持横/纵向扩展。
计算存储分离:计算节点和存储节点,可以独立扩缩容,秒级伸缩。
存储性能和成本:高性能存储栈,支持利用云盘和对象存储进行分级存储。
查询引擎支持矢量化查询,提供丰富的时序计算函数。
支持多种时序协议写入和查询,提供外部组件导入数据。
云边端协同,提供边端与公有云融合的能力。
原生支持多租户,通过配额限制租户资源使用。
支持云原生,支持充分利用云基础设施带来的便捷,融入云原生生态。
介绍
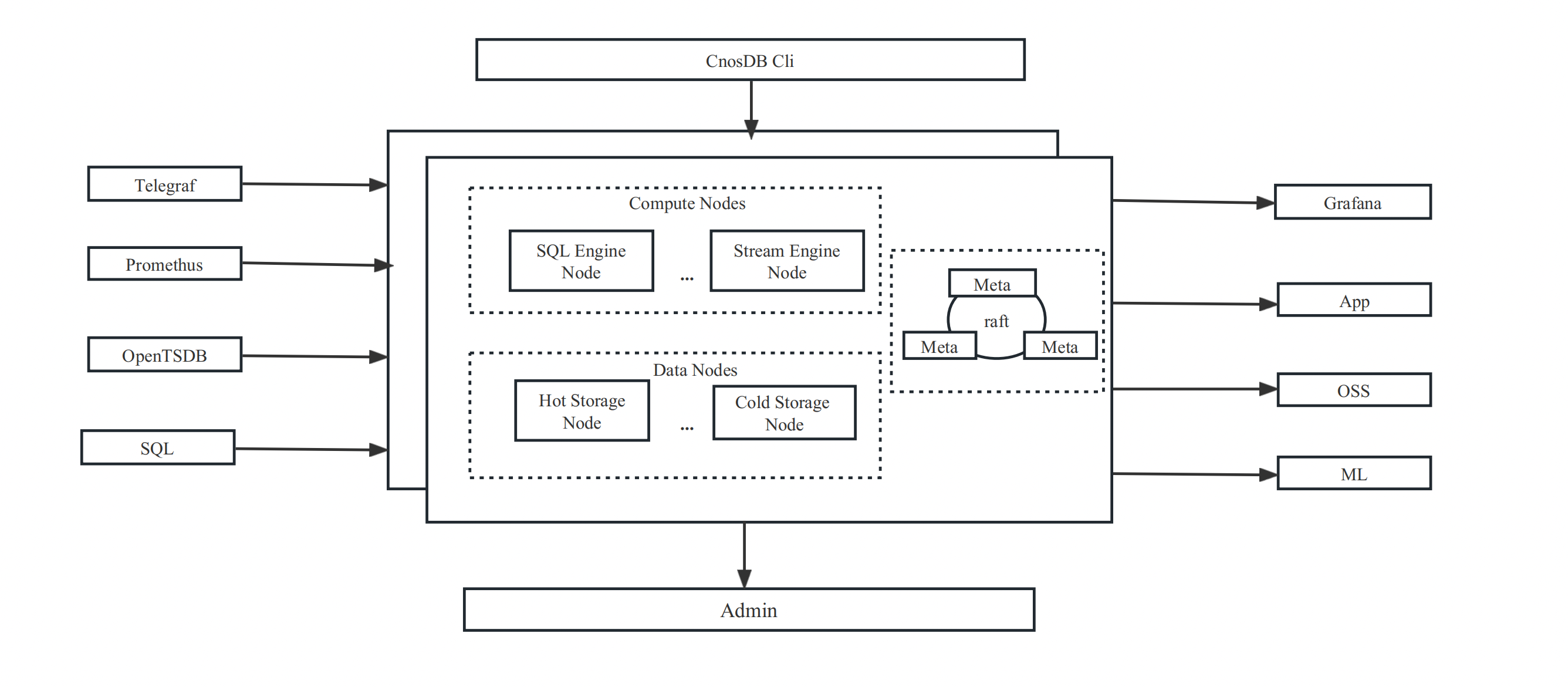
CnosDB 架构由两类进程组成:cnosdb server(cnosdb)和 cnosdb meta(cnosdb-meta)。支持在线水平扩展,允许动态增加节点,并具备元数据和数据备份功能,确保集群稳定。此外,CnosDB 支持大部分 SQL 语法,用户可以通过 cnosdb-cli 客户端轻松连接进行查询和数据导入。
CnosDB
CnosDB,对应程序命名为 cnosdb ,作用是查询和存储数据。cnosdb 内部划分成两个服务:query 查询服务和 tskv 存储服务 ,这两类服务是 cnosdb 的核心。
Query:查询服务,流查询服务,主要负责sql解析,查询规划优化,物理计划执行。用户可以灵活的配置Query节点是否启动流处理模式,可以根据自己的业务灵活的配置Query节点的处理模式。
Tskv:存储服务主要负责索引数据和时序数据的存储和数据读取过滤,tskv 可以根据配置作为冷数据节点和热数据节点,数据会根据冷却时间自动从热数据节点迁移到冷数据节点平衡存储性能和成本详见 分级存储。
ConsDB Meta
cnosdb meta,对应程序命名为 cnosdb-meta ,作用是维护集群的一致性。它存储了集群中的元数据,其中包括集群的租户信息、用户角色信息、拓扑结构、副本的分布以及数据的分布等信息。 cnosdb meta 集群是基于 raft 的强一致性共识协议所以通常在一个分布式集群服务中,建议部署 2n+1 个 cnosdb-meta 服务,这样可以保证集群的高可用性。
CnosDB 在 meta 集群中做了如下的一些优化:
对访问频繁的数据进行 cache 和本地化存储。
schema 信息在本地存储后,订阅来自 meta 集群的 schema version 变更,缓解 meta 集群读压力。
meta 集群分担 leader 压力,提供 Follower Read 方案,读性能得以优化。
CnosDB生态工具
CnosDB Cli 是自带的命令行工具,用于连接 CnosDB 进行 SQL 查询和 line protocol 格式文件的导入。
CnosDB支持多种写入协议,如:SQL line protocol、opentsdb、prometheus, eslog,未来还会添加 trace 等不同协议使用不同的接口,每种协议可以根据配置启用或者禁用,满足用户不同的需求。
Grafana 是一个开源的数据可视化工具,支持多种数据源,CnosDB 提供了 Grafana 插件,用户可以通过 Grafana 插件连接 CnosDB 进行数据可视化展示及告警。
CnosDB 支持通过 JDBC 连接,用户可以通过 JDBC 连接 CnosDB 进行数据查询。
CnosDB 提供了一套完整的 Restful API 接口,用户可以通过 Restful API 进行数据的查询和写入。
CnosDB 提供了python SDK,用户可以通过 python connector 方面的与机器学习系统进行集成。
CnosDB 支持多种agent的写入 telegraf、vector、filebeat 等,用户可以通过配置 agent 将数据写入到 CnosDB 中。
CnosDB Admin 是一个企业版工具 提供可视化的 集群的监控和管理,提供集群的监控、告警、日志查看、集群配置、集群扩缩容等功能,方面企业用户对多集群进行管理和运维。
CnosDB的生态工具还在进一步的完善中 详见 CnosDB生态工具
部署模式
CnosDB 支持多种部署模式:单机、分布式、存算分离、存算一体 通过这些灵活的部署模式可以满足用户多种复杂场景下的部署需求。
cnosdb run -M singleton
cnosdb run -M query
cnosdb run -M tskv
cnosdb run -M query_tskv
数据隔离
query 层
在 DataFusion 中,catalog 隔离关系分为
catalog/schema/table。我们利用这种隔离关系, 我们利用这种隔离关系,将租户之间的隔离关系拆分为tenant/<namespace>/database/table。table 对应于具体数据库中的一个表,提供该表的 schema 定义,并实现 TableProvider。
database 对应于具体数据库中的一个数据库,管理多个表。
namespace 对应于 catalog。每个租户独占一个 catalog,不同租户看到的数据库是不同的,且不同租户可以使用相同的数据库名称。当用户登录时,session 中会获取 TenantID,从而看到自己默认所在的 namespace,实现了软隔离。
tskv 层
在上面的介绍中提到的目录分割策略为
/tenant/db/vnode_id,数据的划分规则请查看 数据分片与复制每个 Node 节点上都有一个实例,称为 tskv,负责保存当前 Node 上所有 Vnode 的信息。每个 Vnode 的数据都保存在独立的目录中。根据数据库中的 TTL 参数管理数据的生命周期。此外,这种策略还便于进行数据目录的大小统计,以便对租户进行计费。