存算分离
Design Objectives
Consdb2.0 is developed in Rust language, based on its security, high performance and community influence, provides users with an excellent time series database and forms a complete DBaas solution.
Time series database
- Extensive: Theoretically supported time series has no limit, completely solves the problem of time series expansion, and supports cross-river expansion.
- Calculate storage separation: Calculating nodes and storage nodes, can expand and shrink capacity independently and on a second scale.
- Storage performance and cost: High performance io stacks support hierarchical storage using cloud discs and object storage.
- The query engine supports vector queries.
- Supports multiple time series protocols to write and query, providing external component import data.
Cloud Native
- Support cloud native, support the full use of cloud infrastructure to integrate into cloud native ecology.
- High availability, second-level failure recovery, support multi-cloud, cross-regional disaster preparedness.
- 原生支持多租户,按量付费。
- The CDC log provides subscriptions and distributions to other nodes.
- Provide users with more configuration items to meet multiple-scenario complex requirements for public cloud users.
- Cloud side synergizes to provide the ability to fuse side ends with public clouds.
- Blend the OLAP / CloudA data ecosystem on the cloud.
In the process of redesigning the time series database, we solve a series of problems faced by the current time series database as much as possible, form a complete set of time series data solutions and time series ecosystem and provide DBaas services in public clouds.
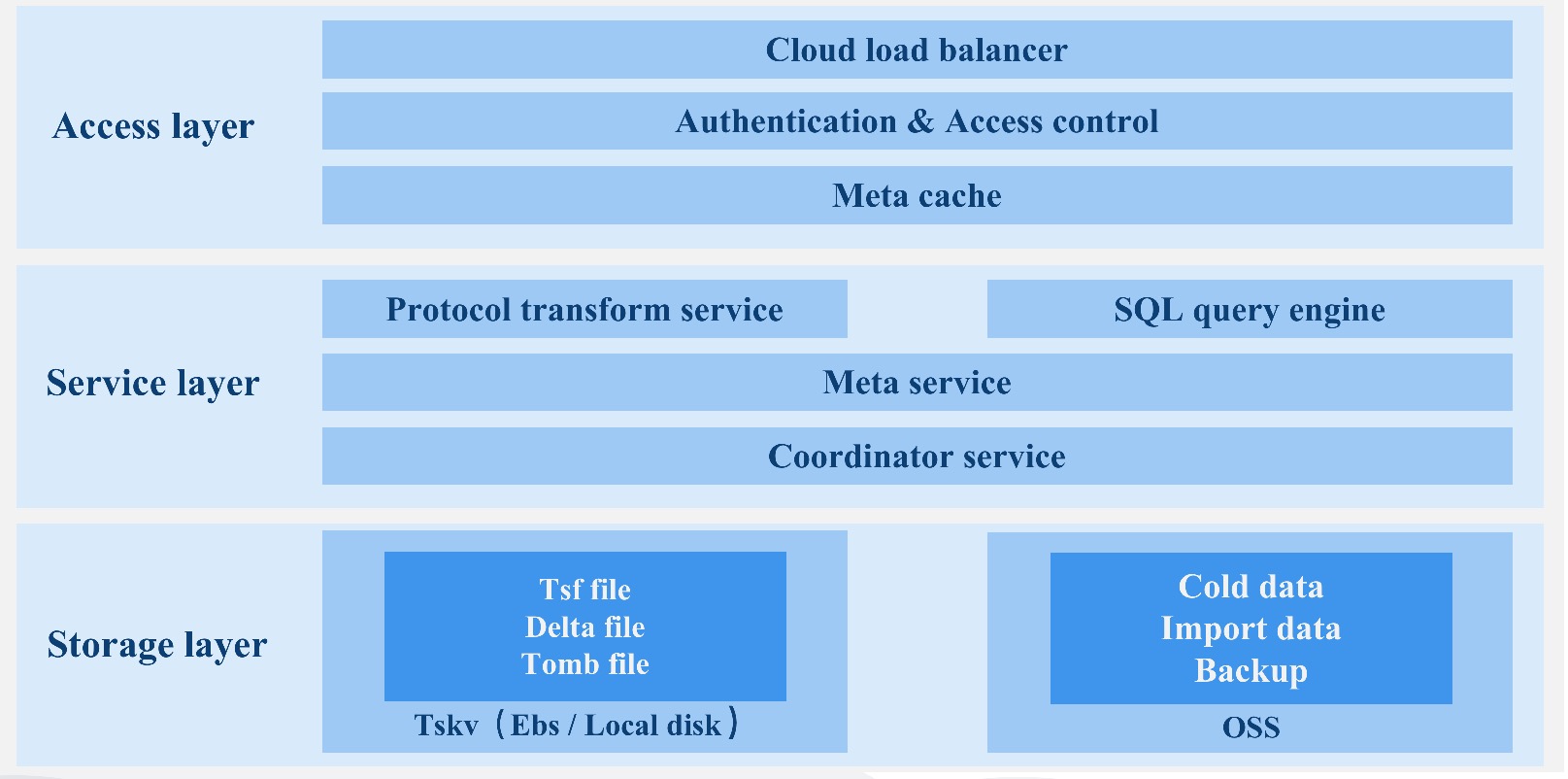
We will have the elaboration from following aspects.
- Data replication and consensus
- Meta cluster
- SQL Engine
- tskv index and data storage
Data replication and consensus
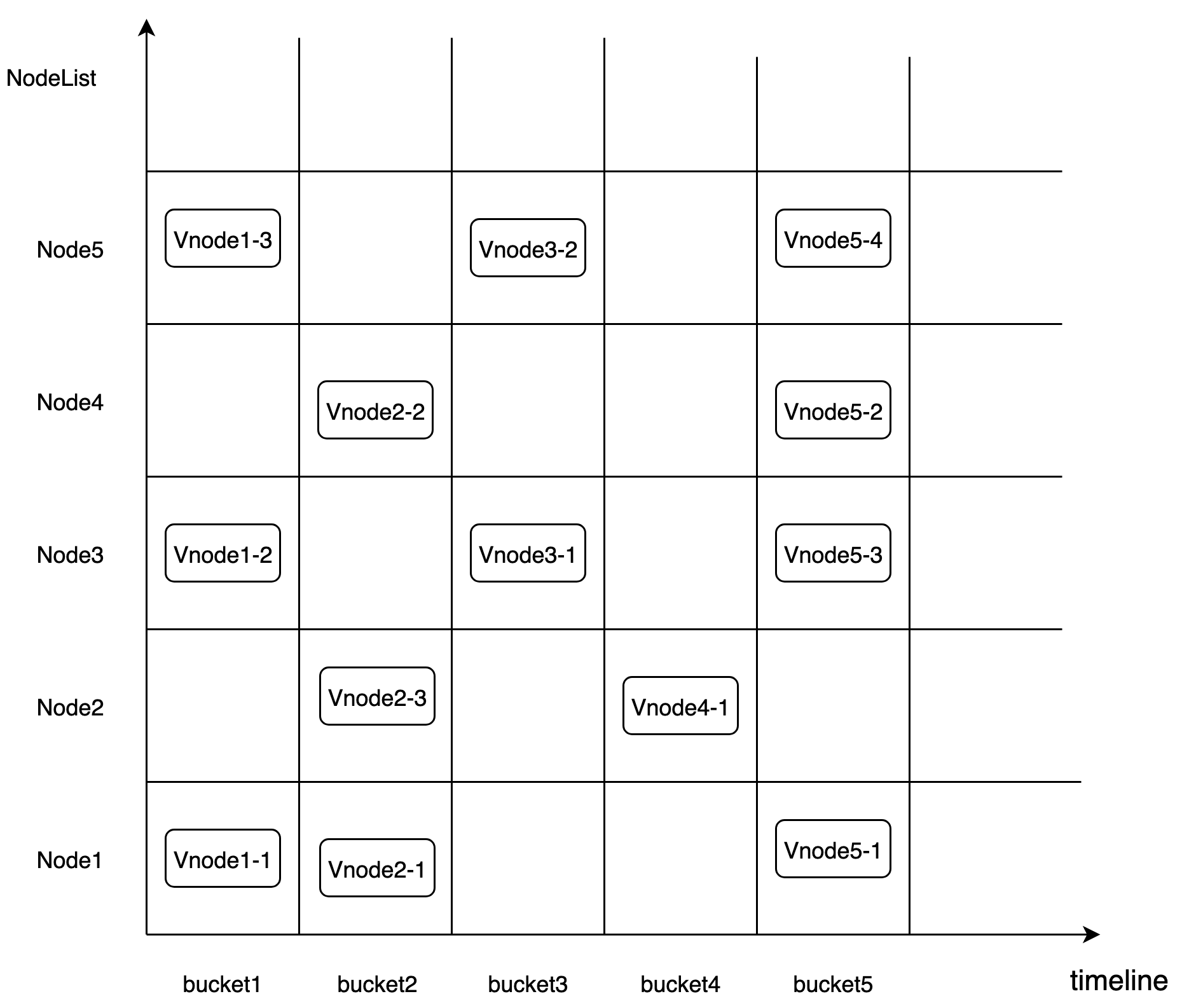
The fragment rule of CnosDB 2.0 is based on Time-range. It uses the fragmentation rule of DB + Time_range to place the data in the corresponding Bucket. Bucket is a virtual logic unit. Each Bucket consists of the following main properties. Bucket creates multiple fragments based on user configurations, dissipating data (suppose data fragment Shad Num is 1).> 「db, shardid, time_range, create_time, end_time, List\<Vnode>」它采用 DB + Time_range 的分片规则将数据放入对应的 Bucket 中。Bucket 是一个虚拟逻辑单元。每个 Bucket 由以下主要的属性组成。 Bucket 会根据用户配置创建多个分片,把数据打散(默认情况下数据的分片 Shard Num 是 1)。
「db, shardid, time_range, create_time, end_time, List\<Vnode>」
The purpose of the operation is:Vnode is a virtual running unit and is distributed to a specific Node. Each Vnode is a separate LSM Tree. Its corresponding tsfamily structure is a separate running unit. 其对应的 tsfamily结构体是一个独立的运行单元。
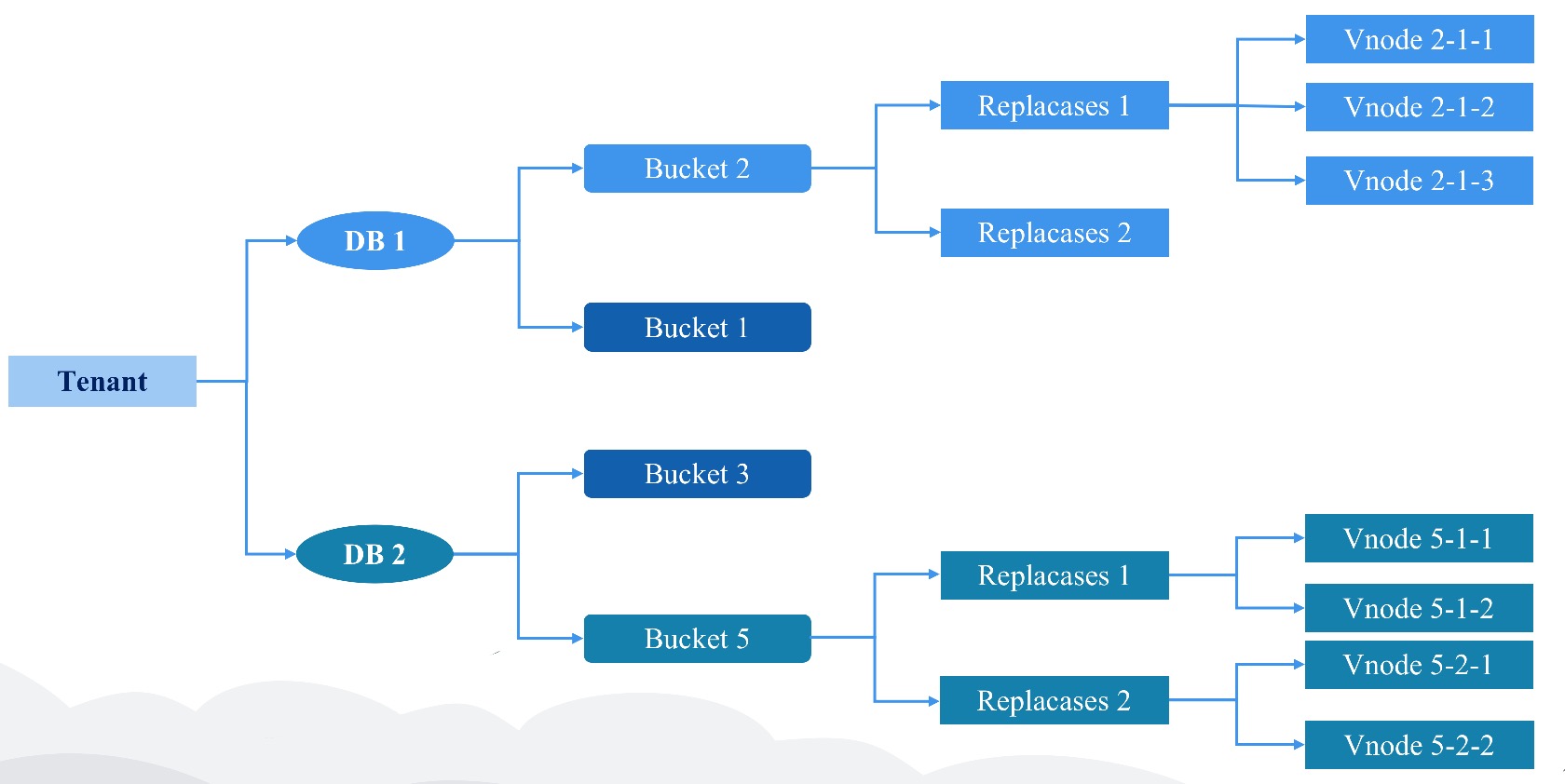
Replicaset
数据的高可用通过数据 replicaset 维护。 每个 db 都会有一个自己的复制组。它表示数据冗余份数。 同一个 bucket 内的一组 Vnode 组成了 一个复制组, 他们之间具有相同的数据和倒排索引信息。
Place Rule
To address the possibility of concurrent failures, the meta node may need to ensure that data copies are located on devices that use different nodes, racks, power sources, controllers and physical locations, when creating bucket. Considering that different tenants will access data at different region, Vnote should be dispatched and discharged by the way of optimal cost.
Data Separation Strategy
Data from different tenants on Node are physically segmented.
/User/db/bucket/replicaset_id/vnode_id
Data Consensus Based on Quorum Mechanism
The Cnosdb2.0 is implemented as a system with final consistency.
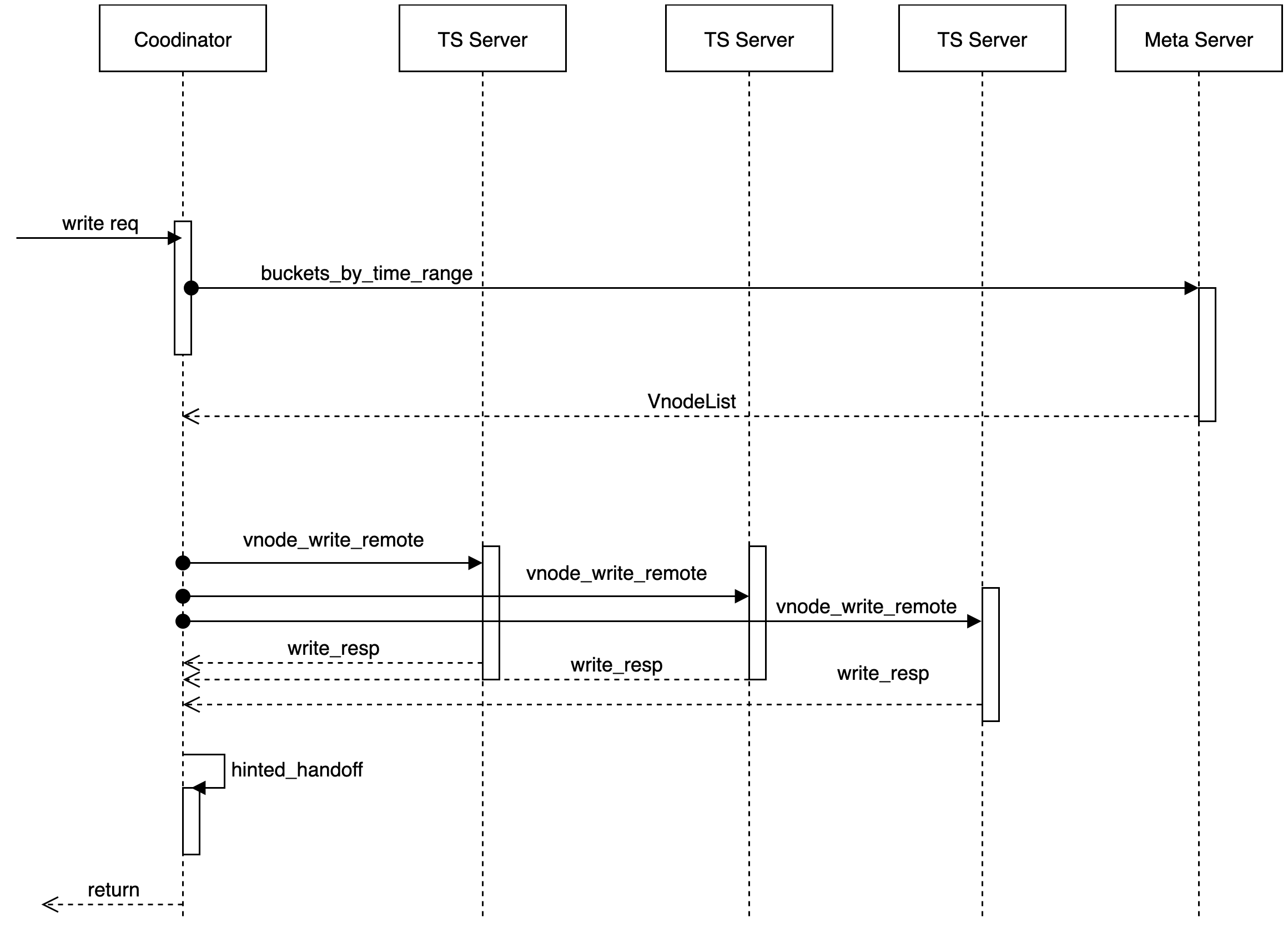
The module using the Quorum mechanism to make data consensuss and handling read or write requests is called codenatoor.
Meta information cache, interact with meta nodes
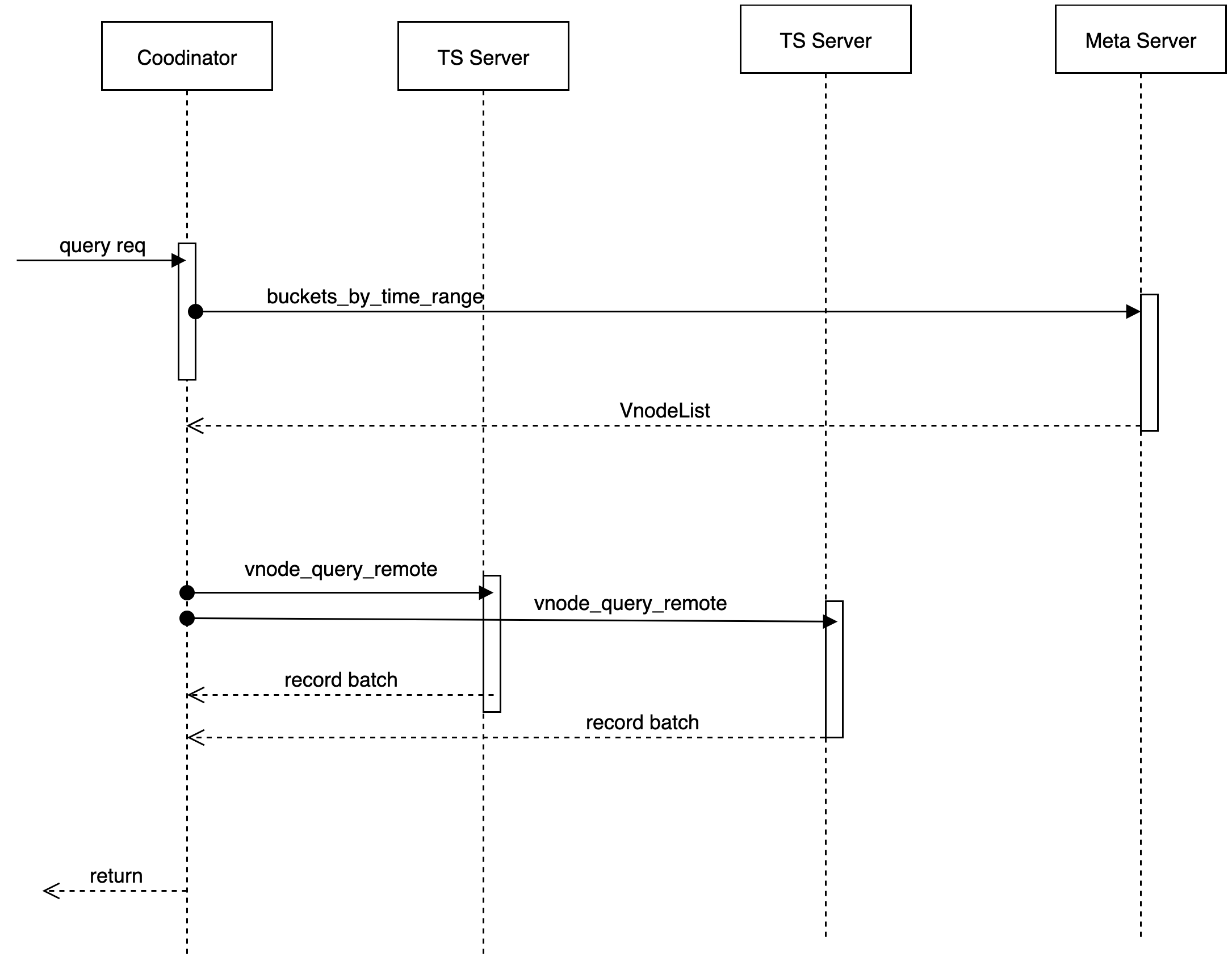
According to user, db, Timemange, get Vnote information, maintain a cache locally and pull VodeList from the remote without a local hit. Provide a trait of Meta Client.提供了一个 MetaClient 的 trait。
Connection management
Manages connections with different tskvs for data reading/writing.
Agent operation for data reading/writing/deleting
Data is configured by users to support a variety of different consistency levels.
pub enum ConsistencyLevel {
/// allows for hinted handoff, potentially no write happened yet.
Any,
/// at least one data node acknowledged a write/read.
One,
/// a quorum of data nodes to acknowledge a write/read.
Quorum,
/// requires all data nodes to acknowledge a write/read.
All,
}Hinted handoff\ Add under the scenario of a temporary failure of the target node to provide the Hinted handoff function of the continator node, which is persistently saved in the Hinted handoff queue of the node, until the copy node fails and then copied and recovered from the Hinted handoff queue.
Data are written
When a write request is received, the cordinator determines the physical node (note) where the data to be stored, based on the partition policy and the corresponding placement rules (place-rule). As long as at least W nodes return to success, the writing operation is considered successful.只要有至少 W 个节点返回成功,这次写操作就认为是成功了。
Data Reading
When a read request is received, the cordinator determines that the physical node (note) where the data to be stored and requires this key corresponding data based on the partition policy and the corresponding placement rules (place-rule), and at present we do not perform the function of read repair (read repair) to initiate only one reading request. In the case of delay in reading, initiate a second reading request.在读延迟的情况下,发起第二个读请求。
Update of Conflicts
- After data creates conflict in a time series scenario, use consistency hash to be replaced by the first copy (replaica) as a confirmation point
- At the same time, the last-write-win strategy is used to resolve conflicts.
Meta Cluster
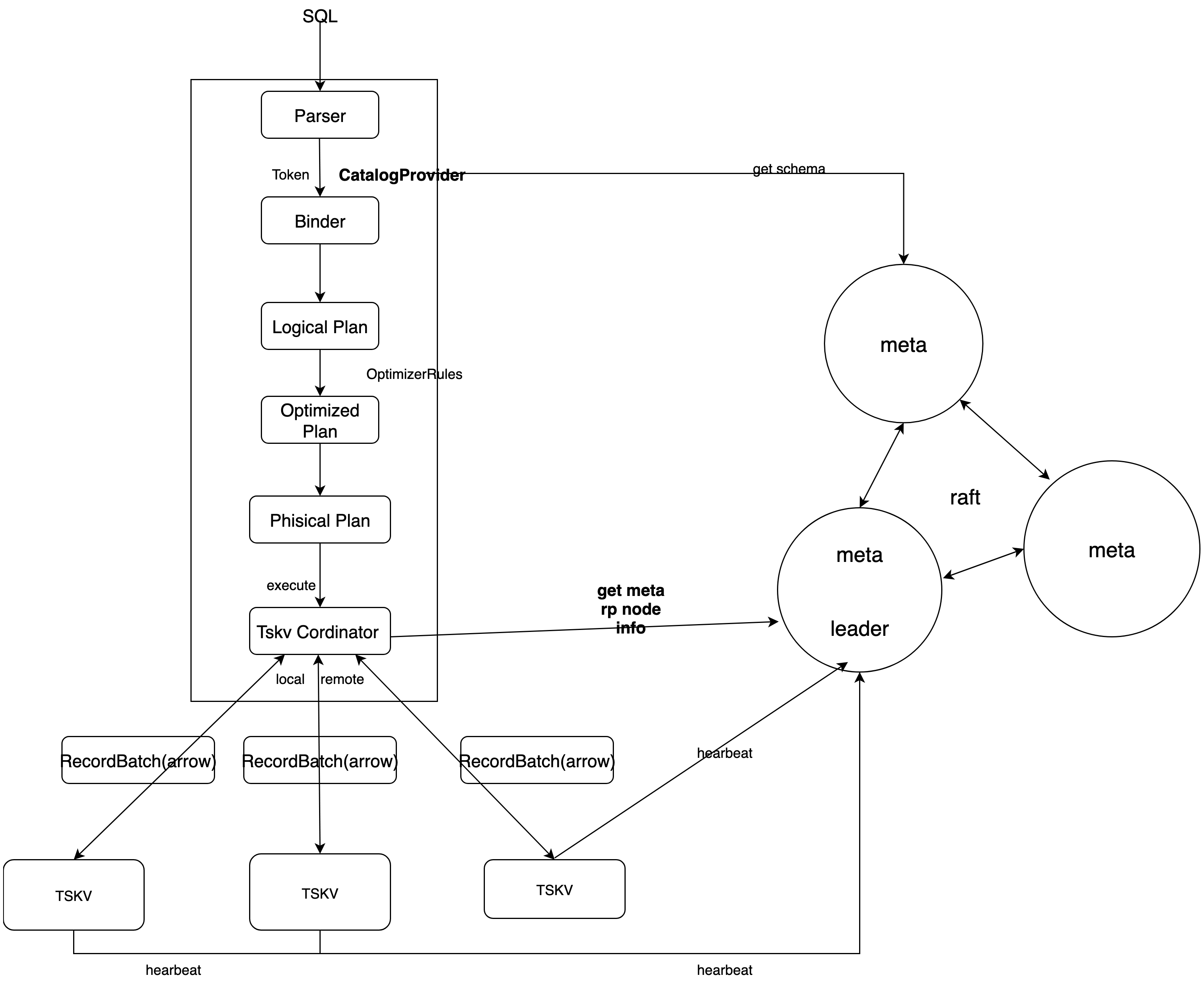
通过 raft 去维护一个强一致性的 meta 集群。Maintain a strong consistency meta cluster through raft. Meta cluster api serves externally, while nodes also subscribe to updates to meta information. All metadata updates are updated through the meta-data cluster.所有的元数据信息的更新都通过 meta 集群进行更新。
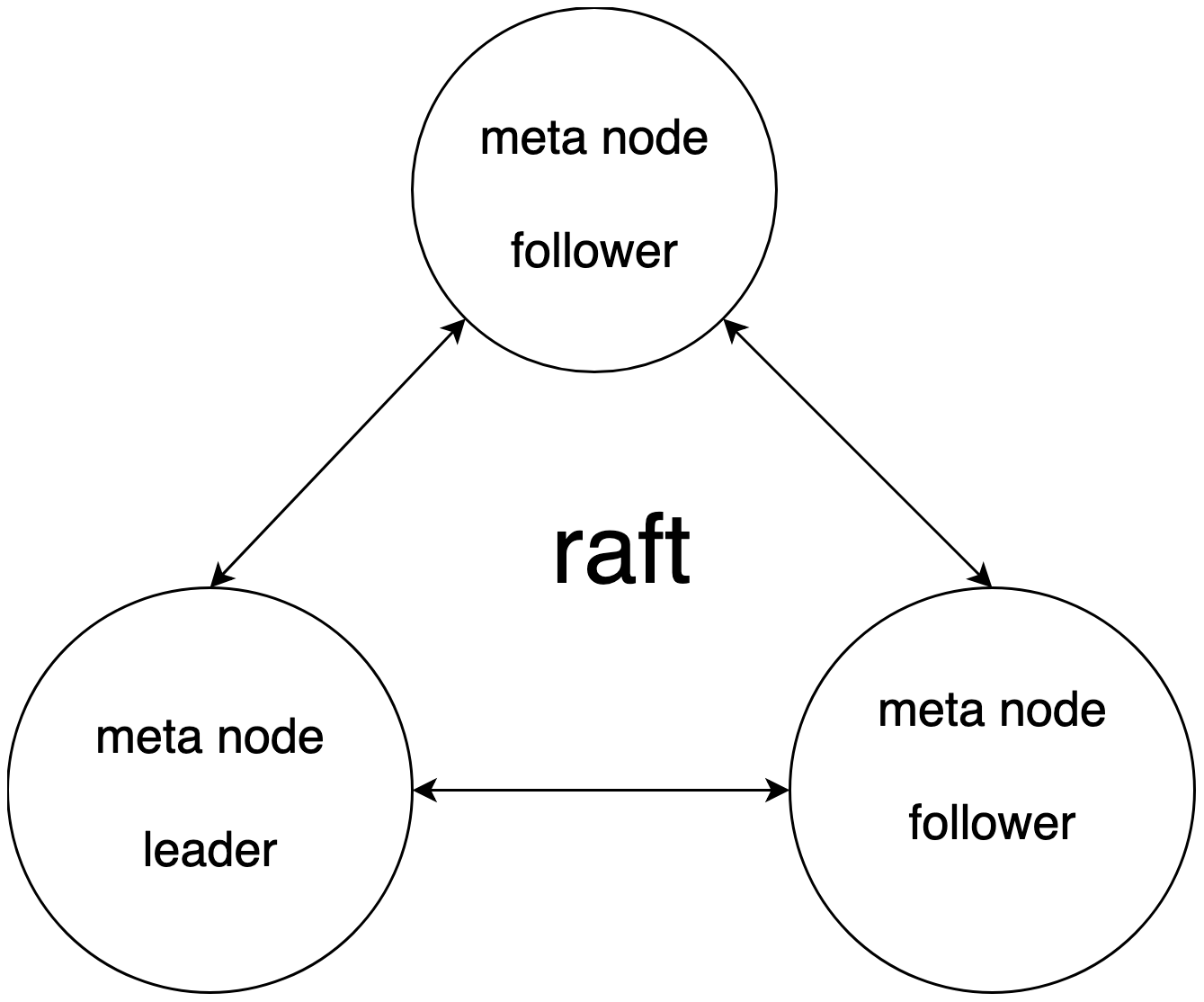
- Database catalog information, DDL operation.
- The node probe/node registration, as well as node load information statistics, is the basis for the read and write selected by coordinator.
- Rent and sub-user information and permissions are relevant.
- Data routing information, the routing information corresponding to vnodeList corresponding to denant / db / bucket / replicaset.
- Provides the functionality of distributed locks and watch change notifications.
We adopt a strong consistency meta cluster and realize corresponding optimization. The specific reasons are as follows:具体原因如下:
- In practice, metadata in our cluster is usually controlled on a smaller scale and without extensible requirements.
- Engineering practice is relatively simple and is conducive to rapid iteration.
- 对访问频繁的数据进行 cache 和 本地化存储,进行优化。 Make cache and localized storage for access to frequently accessible data, optimize. > - After storage locally, subscribe to schema version changes from the meta cluster to relieve the pressure of meta cluster reading. > - Meta clusters share the leveler pressure and provide the Follower / Read scheme. Reading performance is optimized. > - meta 集群分担 leader 压力,提供 Follower/Read 方案。读性能得以优化。
SQL Engine
We used DataFusion as the query engine. DataFusion is an extensible query execution framework, written with Rust, used Apache Arrow As its memory format. DataFusion supports SQL and DataFrame API for building logical query schemes, as well as query optimizers and execution engines that can be executed in parallel with partition data sources using threads. It has the following advantages:DataFusion 支持用于构建逻辑查询计划的 SQL 和 DataFrame API 以及能够使用线程对分区数据源并行执行的查询优化器和执行引擎。具有如下优点:
- High performance: Using the memory models of Rust and Arrow, it has high performance.
- Strong extensibility: Allows almost any point in its design to be extended and customized with a needle-specific use case.
- High quality: DataFusion and Arrow ecology are widely tested and can be used as production systems.
- Fusion of large data ecology: As part of the Apache Arrow ecosystem (Arrow, Flight, Parquet), it is better integrated with large data ecosystems.
By extending DataFusion data sources and providing custom SQL statements, the query process for data under distributed scenarios is as follows:
TSKV Index and Data Storage
tskv mainly undertakes data and index storage, manages all Vnodes on node, each Vnode is responsible for some of the data in a db. In Vnode, three modules mainly make up WAL, Index Engine and Data Engine.Separation Mode
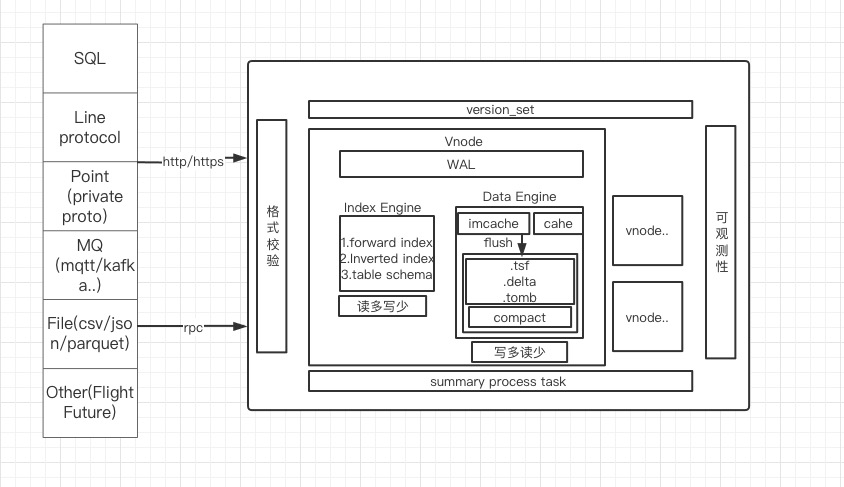
Index Engine
Indexes used to store time series data are usually models that read more and write less, mainly quickly indexing and tagkey-based conditional filtering to filter out the right series.
The main functions are:
- Storage positive index
- Storage reverse index
- Caching catalog information
Common query statements:
SELECT xxx from table where tag1= value1 && tag2=value2 [and time > aaa and time \< bbb] [group by\order by\limit ....]
The design of index is mainly aimed at the where filtering conditions; used to reduce the search scale of data and speed up the query efficiency of data.
Support the following filtering conditions:
- Equal to; not equal to; such as: tag = value, tag! = Value
- More than; less than; such as: tag \< value
- Prefix matching; such as: tag = aaa_*
- Regular expressions; such as: tag = aaa*bbb
Remove data from the flash-request and create a flash_task based on data, executedThe high availability of data can be maintained through data replica set. Each db has its own replica group representing the number of data redundants. A set of Vnotes within the same bucket forms a replica group with the same data and inverted index information.
虽然时序数据库是写多读少,但是写入数据时对索引的使用更多是读取而不是构建。Indexes is built when the data is written. In time series database, each tag is indexed, and the corresponding value of multiple tags is combined into a searchkey. Although time series databases are writing more and reading less, the use of indexes when writing data is more read than build. Time series databases are often written to different time points of the same search, so each search's index information needs to be built only when it is first written, and if the search exists (reading operation), no longer indexed;
Storage structure
Based on the hash function, calculate HashID:
hash (SeriesKey) -> HashID(24-bit integer, about 16 million); 2.HashID (uint64):HashID \< 40 | auto_increment_id -> SeresIDis obtained.FieldID (uint64) is combined by SeriesID with TableFiledID (field has a number within the table for TableFiledID).
Conditions of limitation:
- The number of HashIDs is about 16 million, and hundreds of millions of single machine Series will lead to List lengthening drag-and-seeking.
- SeriesID 的高 24 位有其他用途,只有低 40 位有意义大约是 1 万亿左右。 The 24th bits of FieldID are TableFiledID, and the lower 40 bits are the lower 40 bits of SeresID.
The TSM data file stores FieldID and corresponding Data information. The information about SeresKey is stored in the index file, and the following is about the index data organization.
Design of index data structure
- HashList:
HashID-> List \< (SeriesKey, SereesID) >for SeriesKey to interexamine with SereesID- SereiesKey looks for the SereesID process:
Hash (SeriesKey) -> HashID, getsList \<SerisKey, SereesID >from HashList, and then traverses List for SeriesID. - SereesID looks for the SereesKey process, takes the 24-bit high of SeresID as HashID, and the search process is the same.
- SereiesKey looks for the SereesID process:
TagValue -> List \<SeriesID>implements indexing capabilities for Tag, using tag query conditions filtering.- Query Conditions:
where tag = value, get a list of SeresIDs based on TagValue, and further obtain FieldID loading data from TSM files. - Multiple query conditions intersect and or need to operate multiple
List\<SereesID\>.
- Query Conditions:
- 要求 TagValue 顺序存储可遍历访问。用途
show tag values查询。 HashList 结构需要在内存维护一份,惰性加载。 The TagValue sequence is required to store traverse access. Usedshow tag valuequery HashList structure requires one maintenance, inert loading in memory.HashID-> List \< (SeriesKey, SereesID) >andTagValue-> List \<SeriesID>are persistent.
- HashList:
Data Engine
Data used primarily to store time series data are usually scenes that write more and read less, using LSM models, mainly to write data quickly, while removing expired and deleted data through context. DataEngine is divided into the following modules:DataEngine 分为如下几个模块进行:
WAL module
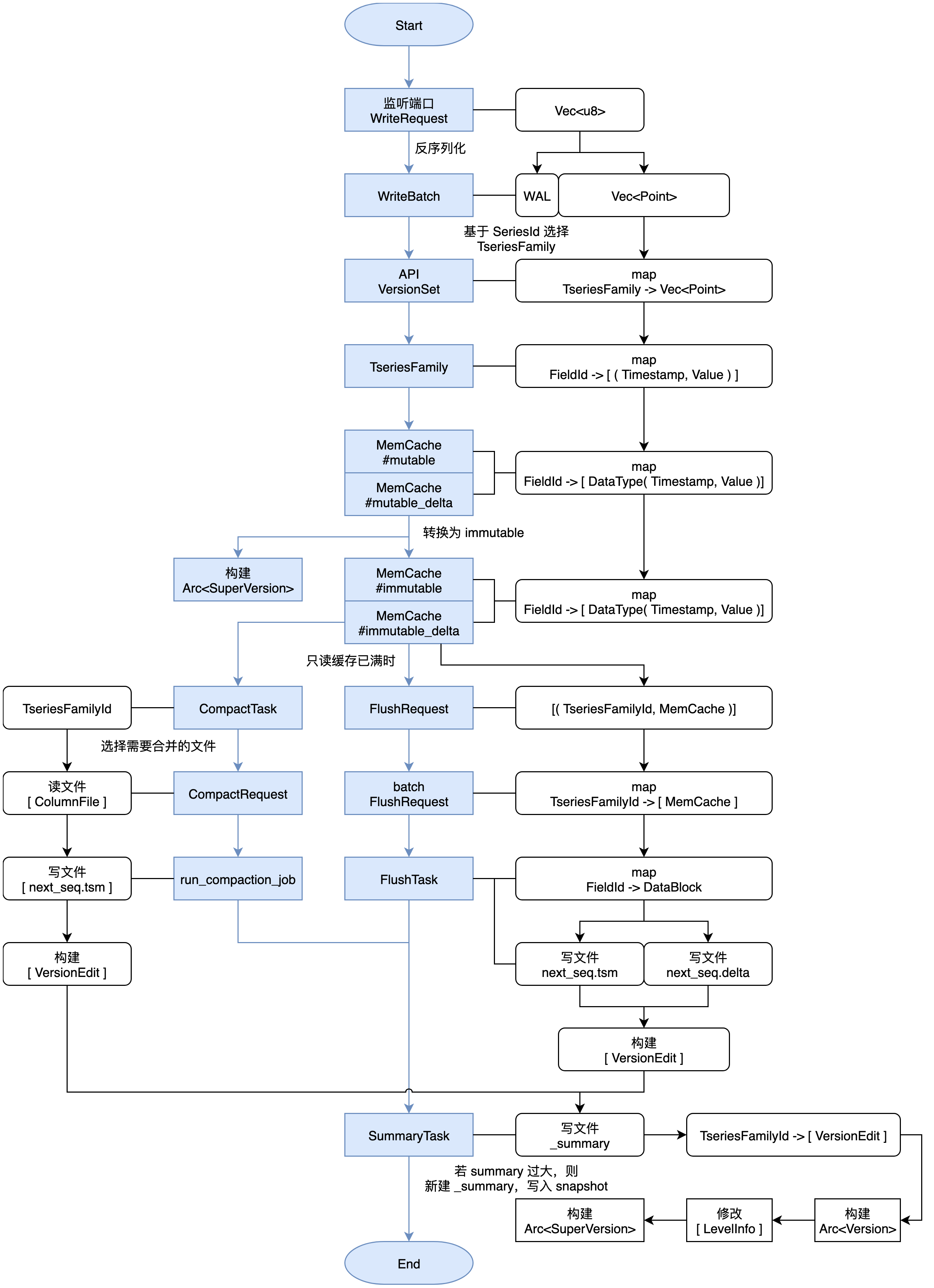
For the pre-log, the WAL applies the write operation to the WAL file on disk before memory is added to the disk before memory, which will be used to restore memory to a state consistent with the collapse. When a write request is received, wal_job first checks whether the current WAL file is full, if it is full, create a new one, and then start writing it in a certain format. Each req corresponds separately to a seq-no, seq-no increment to record how many batches have been written since it started. The wal_job thread returns this seq_no to the main thread. Each point of the same batch has the same seq_no in memory or written to TSM, which is processed for seq_no.当接收到写入请求后,
wal_job首先会检查当前WAL 文件是否已满,如果满了就新建一个,然后开始按照一定格式将内容写入文件中。每一个req单独对应一个seq-no,seq-no递增,用来记录开机以来有多少批次已经被写入。wal_job线程会将这个seq_no传回主线程。同一批次的每个point都有相同的seq_no写入内存或写入成TSM时都会针对seq_no进行一定的处理。TimeSeriesFamily
TimeSeriesFamily, a storage unit for time-order data that saves metadata for data in corresponding memory and data in corresponding disks, typically abbreviation for tsfamily, and before we write data, we generate SeresID and FieldID based on the tag and Field of the data. Coordinator gets Bucket based on db and Timemange and gets TseriesFamilyID to write data to tsfamily based on hash (SeriesID) % shard_nums. The tsfamily members are as follows:coordinator 根据 db 和 time_range,获取 bucket,根据
hash(SeriesID)% shard_nums获取 TseriesFamilyID 向 tsfamily 写数据。 tsfamily 成员如下:pub struct TseriesFamily {
tf_id: u32,
delta_mut_cache: Arc \<RwLock \<MemCache>>,
delta_immut_cache: Vec \<Arc \<RwLock \<MemCache>>>,
mut_cache: Arc \<RwLock \<MemCache>>,
immut_cache: Vec \<Arc \<RwLock \<MemCache>>>,
super_version: Arc \<SuperVersion>,
super_version_id: AtomicU64,
version: Arc \<RwLock \<Version>>,
opts: Arc \<TseriesFamOpt>,
seq_no: u64,
immut_ts_min: i64,
mut_ts_max: i64,
}tf_id: tthe identifier of tsfamily, each tsfamily has the only tf_id.mut-cache: For the latest data written in a cacheimmut-cache: When the mut-cache is full, turn toimmut-chache,immut-cacheflash to disk to generate TSM files.super-version: Snapshot data from the currentmut-cacheandimmut-cacheof tsfimily.version: Maintains snapshots of disk data in the current tsfaimily.Recover and Summary
Summmarry is a metadata file generated by changes in the version of the TSM file, which stores the sample file. The system file stores version-change metadata version_edit for outage recovery of
version_setmetadata. The node runs for a long time to generate larger summary files, and we regularly integrate the summary file to reduce the time of outage recovery.summary 文件中存储着版本变更元信息version_edit,用于宕机恢复version_set元数据。node 节点长时间运行会产生较大的 summary 文件,我们会定期将 summary 文件进行整合。减少宕机恢复的时间。tskv first performs the recover function when creating:
- Gets the summary structure from the sample file.
- According to the
last_seqof ctx of the schema structure, know which batch has been filed by flush - According to the wal file and
last_seq, the base that is not rewritten into memory by the flush - Restore
version_setbased on the summary file
Flush
当 tsfamily 中
immut-cache容量达到一定程度后,就会开始进行 flush。 When theimmut-cachecapacity in tsfamily reaches a certain extent, the flash starts after the execution of the write operation, when it is found that theimmut-cacheis full, pack it into aflash_request, which is received by theflash_jobthread after processing.- 将
flush-request中的数据取出,根据数据创建一个flush_task,执行。 - According to
TseriesFamilyID, FileID creates a TSM file that writes data to the TSM file - According to file information, the application metadata corresponds to the
Levels_infoof the version - Generate versioned it based on modifications to version and
seq-no, TseriesFamilyID, etc - Send all generated
version editto thesummary_task_sendercreated together at the time of creation of tskv, and the thread receives the request and starts processing, and writes theversion_editto the summary file.
- 将
compaction
We use the class LSMtree method to sort data. Typically, data from time series databases are written in chronological manner. But IoT has scenarios that make up data, leading to time stamps. In addition, it is difficult to ensure the order of writing for all users due to network delays in public cloud scenarios. In the face of multiple complex write-in scenarios, we need to consider a variety of complex scenarios when performing data.Native support multi-tenant, pay on schedule.但在 IoT 会有补录数据的场景,会导致时间戳陈旧的问题。 除此之外,因网络延迟在公有云的场景下很难保证所有的用户的写入顺序。面对多种复杂的写入场景,我们需要在对数据 compaction 的时候考虑多种复杂的场景。
compaction 的目的有:
- Aggregate small tsm files to generate larger tsm files.
- Clean up files that have expired or marked to delete.
- Reduce reading magnification and maintain the metadata of
level_infoin our current version.
level_range compaction
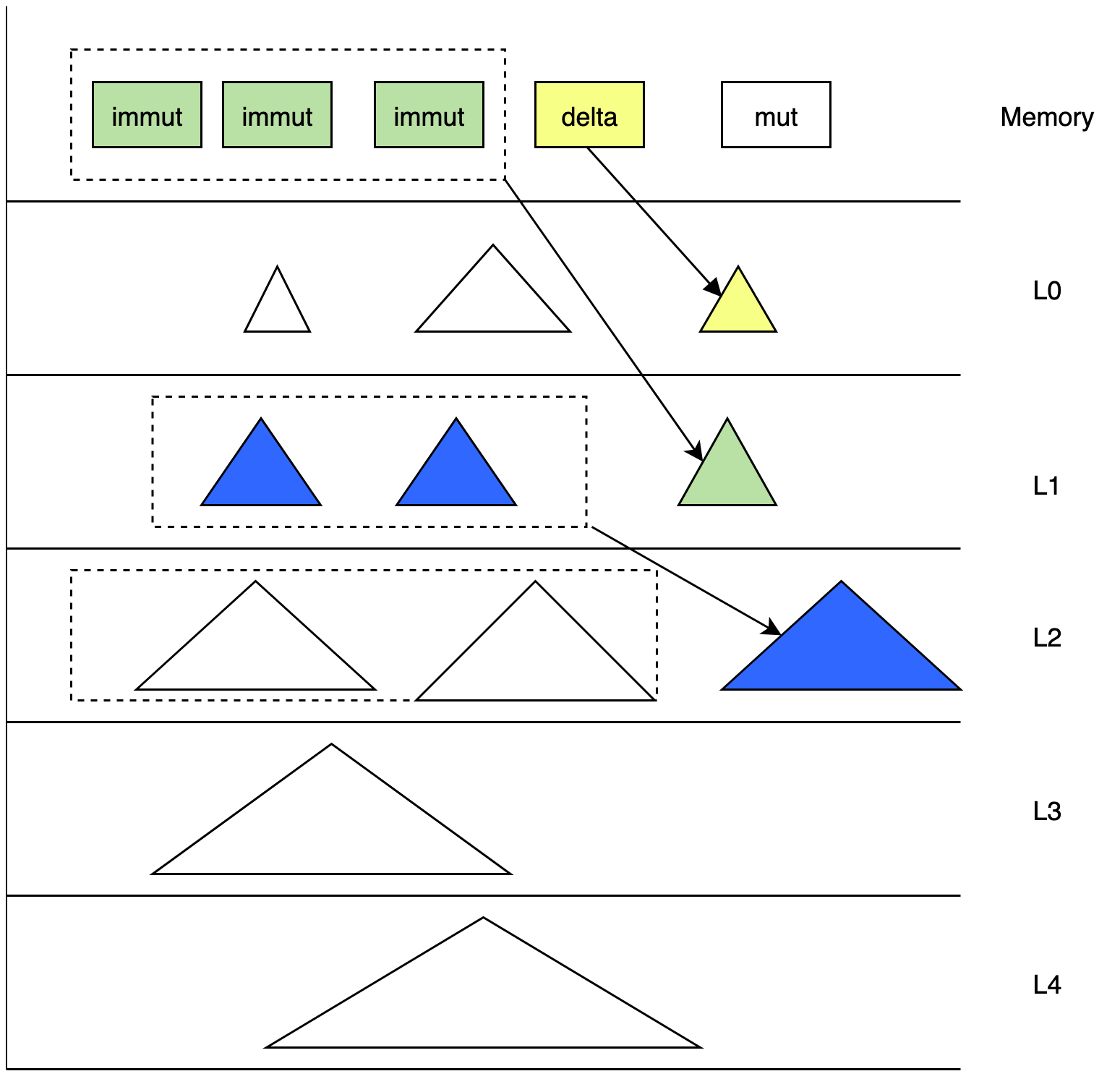
- Typically, time series databases are written in order to respond to disorderly data, we add delta files. The data of Delta is brushed to the L0 layer.delta 的数据会刷到 L0 层。
- 从 L1 到 L3,
LevelInfo中的数据是按照时间进行分层排放的。 From L1 to L3, The data ofLevelInfoare classified by time. Each layer has a fixed time range and does not overlap, and the data in memcache has a fixed timerange. Each layer of time is dynamically updated when it works or flashes.每一层的时间范围都会有在 compaction 或者 flush 的时候进行动态更新。 - 每次新写入的 TSM 文件都具有本层最新的时间范围。Each newly written TSM file has the latest time range of the layer. That is,
TimeRange ( ts_min, ts_max),ts_maxis the largest in the time range held by file id largest TSM file in the L0 layer. - Writer ProcessThe pick process of the compact creates a virtual
time_window.time_windowselects the appropriate TSM file in this layer for compaction to the next floor, while updating the data of this layerLevel_info. Update TSMin inLevel_infoto maximum timestamp oftime_window, the time range of this layer goes forward. The newly generated TSM file is placed on the next floor and ts_max of the next layer is propelled to the maximum value oftime_window.将level_info中 TSMin 更新到time_window的最大时间戳,即本层的时间范围向前推进。新生成的 TSM 文件会放入到下一层,下一层的time_range的ts_max推进到time_window的最大值。 - At the beginning of L3, the TSM file is divided by directory by table; and the same table TSM file is placed together. Supports the generation of the parquet file and is graded on S3. 支持生成 parquet 文件 放到 S3 上进行分级存储。
time_window compaction
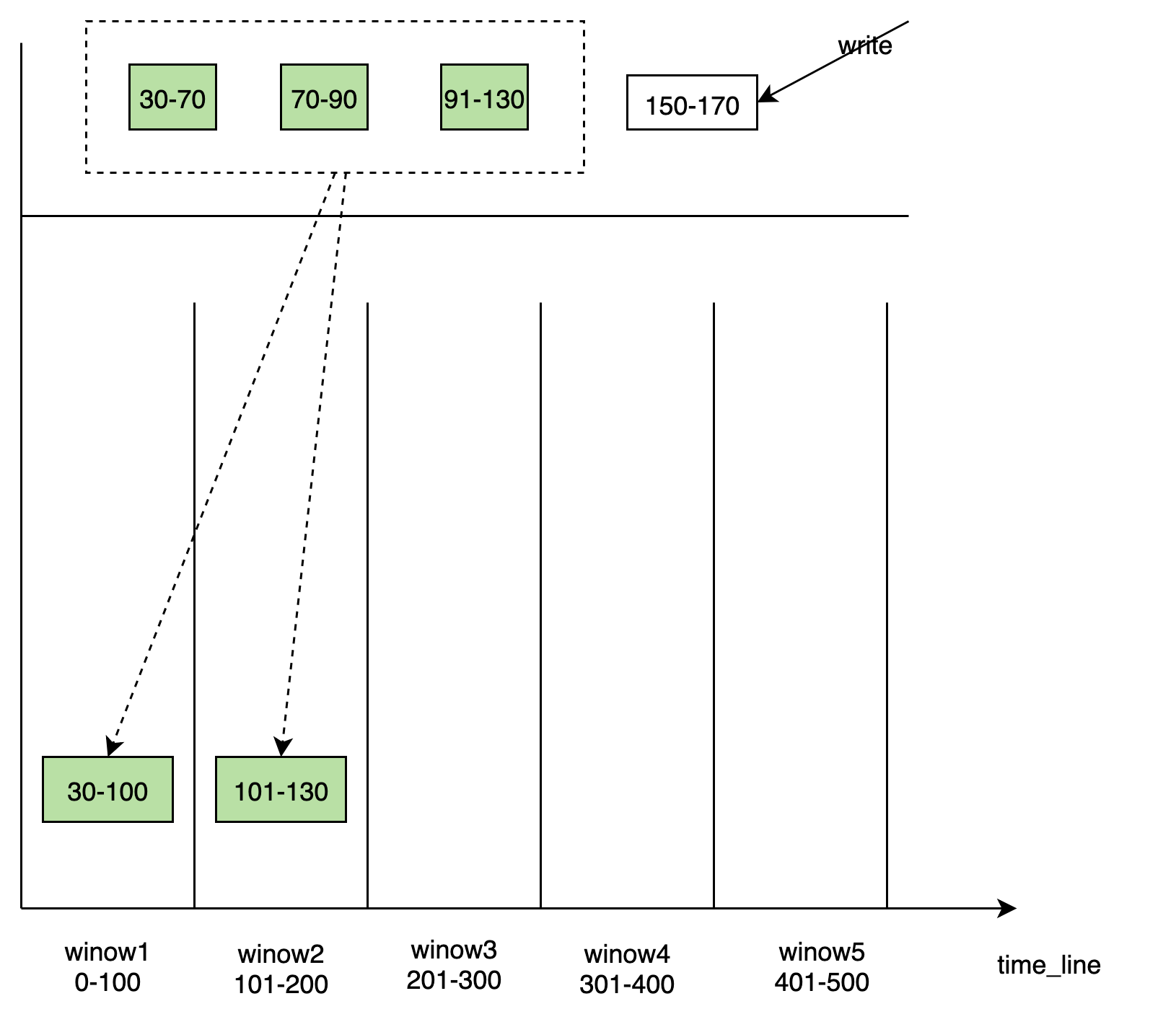
Window-based components are performed in different lev_lange modes, from immut_cache flash to disk, generating different TSM files into the corresponding windows based on the time range of TSM, and windows are created dynamically over time. Each windows is responsible for writing for some time.每个 window 负责一段时间内的写入。
There are some discrete data tsm file blocks within windows that need to be merged to generate larger file blocks. The windows internal maintains a list of metadata about files. Compared with the mode of integration with Level_range, the performance of time_window reduces the amplification of writing. window 内部会维护一个关于文件的元信息一个列表。 相比与
level_range的合并方式,time_window的 compaction 方式会减小写入的放大。
data_engine data stream
Other System Design
Concession of tenants
query layer
In DataFusion, the catalog isolation relationship is divided into
catalog/schema/table. We use this isolation relationship, which is separated between tenants astenant (namespace) / database / table.Separation ModeTable corresponds to a specific table in a specific database that provides a specific table schema definition implementation TableProvider
Database corresponds to a dataabase, which manages multiple tables under a specific database.
namespace对应 Catalog。 Namespace corresponds to Catalog. Each tenant occupies only one catalog, and the db seen in different tenants is different, and different tenants can use the same Database name. When the user logs in, take TenantID in the session by default to see his namespace, which means namespace has a soft isolation effect. 用户登陆的时候在 session 中拿到 TenantID 默认看到自己所在的 namespace,这个意义上 namespace 有软隔离的作用。
tskv layer
The directory segmentation policy mentioned in the above introduction:
/User/db/book/replicationset_id/vnode_id/tskvis an instance on each Node node. Save all Vnote information on the current Node. Each Vnode saves the data under a separate directory. Clean up the data based on the configuration db retion policy. At the same time, we can easily carry out the data directory size statistics, the tenant is billed. tskv 是每个 Node 节点上的一个实例。保存当前 Node 上所有的 Vnode 的信息。每个 Vnode 把数据保存在单独的目录下。根据配置的 db retention policy,将数据清理掉。同时我们可以方便的进行数据目录的大小统计,对租户进行计费。