Log ecology
Vector
Vector是一个高性能的可观测数据管道,使组织能够控制其可观测数据。收集、转换并将所有log、metric路由到现在正在使用的任何供应商,或者未来可能想要使用的任何其他供应商。Vector可以在你最需要的地方(而不是供应商最方便的地方)大幅降低成本,使数据更加新颖丰富,并提供数据安全性。Vector是开源的,并且比任何替代方案快接近10倍。
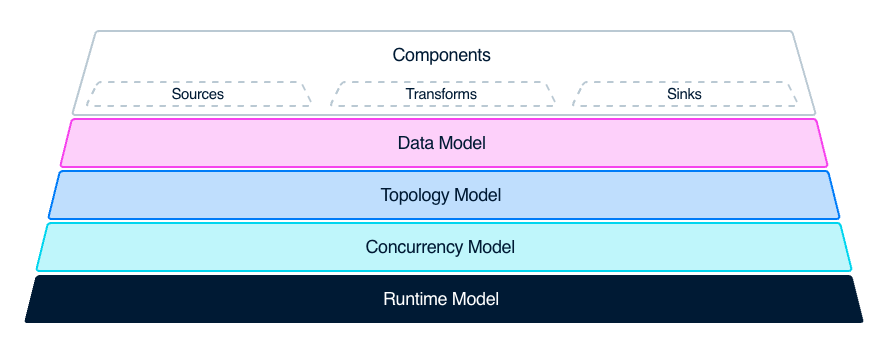
拓扑模型
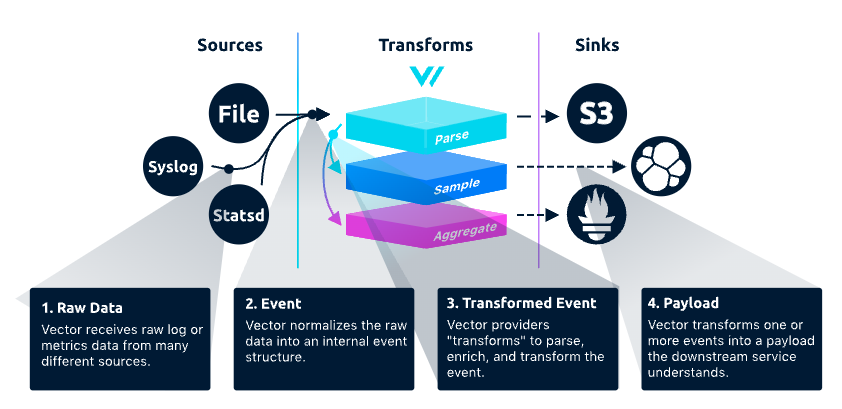
Vector 主要有三大功能模块:Sources,Transforms,Sinks
数据从 Source 进入到 Vector,经过一些 Transforms 逻辑进行数据加工,最后发往 Sink。Vector 通过 Source、 Transform 、Sink 三种不同类型的组件组成了一个完整的数据流水线。
Source 就是一个可供采集的数据源,例如文件、Kafka、Syslog 等。而一个 Sink 则是接收、消费数据的终端,比如Clickhouse、Splank、Datadog Logs 这类的数据库,或者日志分析平台。
Transform 用于对数据流进行转换、修改和过滤,以满足特定的需求。它可以对输入数据进行多种转换和处理,例如重命名字段、过滤数据行、添加新字段、删除字段等。使用transform组件,可以将数据转换为所需的格式,并将其路由到正确的目标。支持多种转换方法,包括grok、JSON、CSV、regex、lua等。它还支持多种数据格式和协议,例如JSON、YAML、CSV、Syslog、HTTP、TCP等。
Sink 是经过处理和转换的数据流需要被发送到的目标存储或分析系统。Vector支持多种类型的sink,包括文件、标准输出、TCP/UDP、HTTP、Kafka、S3、Elasticsearch、Datadog、InfluxDB等
简单归纳一下 Vector 具备的两种主要类型的功能:
● 数据采集与传输
它可以从数据采集端的 Source 获取数据,并最终传输到数据的消费端 Sink。
● 数据加工的能力
可以通过内部的 Transform 的功能模块对收集到的数据进行解析、采样、聚合等不同类型的加工处理。
Vector 用法介绍
作为一个工具,vector的易用性很高。
它支持通过很多不同的方式安装,安装包下载、包管理器等等,安装完成以后,得到一个二进制的 Binary,它唯一的依赖就是一个配置文件。
编辑配置文件 vector.toml
# Change this to use a non-default directory for Vector data storage:
data_dir = "/tmp/cnosdb/lib/vector"
# Random Syslog-formatted logs
[sources.logs]
type = "file"
include = [ "/tmp/cnosdb/1001/log/tsdb.log.*" ]
# Parse Syslog logs
# See the Vector Remap Language reference for more info: https://vrl.dev
[transforms.parse_logs]
type = "remap"
inputs = ["logs"]
source = '''
.message, err = parse_regex(.message, r'(?P<timestamp>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+[\+\-]\d{2}:\d{2})\s+(?P<log_level>[A-Z]+)\s+(?P<module>[\w:]+):\s+(?P<message>.+)')
if err != null {
log("Error parsing log: " + err)
}
'''
[sinks.cnosdb]
type = "elasticsearch"
inputs = ["parse_logs"]
endpoints = [ "http://127.0.0.1:8902/api/v1/es/_bulk?table=t1&time_column=date&tag_columns=node_id,operator_system" ]
auth = {strategy = 'basic', user = "root", password = ""}
healthcheck = {enabled = false}
配置文件中的配置大体上分三种类型:sources,transforms,sinks,概念与之前提到的相同。
每个组件都有一个唯一的id,并以组件的类型作为前缀。
第一个组件为sources,id为generate_syslog,类型是demo_logs,以syslog为模板,100条数据。
第二个组件为transforms,id为remap_syslog,inputs告诉我们它接收的数据来源为generate_syslog,transform类型为remap,remap是vector在处理数据方面的一个强大的transform,提供了一种简单的语言,称为Vector Remap language,它允许你解析、操作和装饰经过Vector的事件数据。使用remap,可以将静态事件转换为信息数据,帮助询问和回答有关环境状态的问题。这里执行了一个parser_syslog函数,参数传入了message,将这个syslog解析成结构化事件。
第三个组件为sinks,id为emit_syslog,接收的数据来自于remap_syslog,类型为终端,将数据以json形式输出。
运行这个命令
vector --config vector.toml
将会在终端看到一些json形式的events,类似这些:
{"appname":"benefritz","facility":"authpriv","hostname":"some.de","message":"We're gonna need a bigger boat","msgid":"ID191","procid":9473,"severity":"crit","timestamp":"2021-01-20T19:38:55.329Z"}
{"appname":"meln1ks","facility":"local1","hostname":"for.com","message":"Take a breath, let it go, walk away","msgid":"ID451","procid":484,"severity":"debug","timestamp":"2021-01-20T19:38:55.329Z"}
{"appname":"shaneIxD","facility":"uucp","hostname":"random.com","message":"A bug was encountered but not in Vector, which doesn't have bugs","msgid":"ID428","procid":3093,"severity":"alert","timestamp":"2021-01-20T19:38:55.329Z"}
Vector 与 CnosDB 集成
尽管目前Vector还没有支持CnosDB的Sink,但是由于CnosDB针对Vector做了数据导入的原生支持,用户可以通过类型为vector的Sink 直接把数据导入到CnosDB。
写入Vector Log
vector配置文件如下
data_dir = "/tmp/vector"
[sources.in]
type = "file"
include = ["/tmp/MOCK_DATA.json"]
[transforms.json_transform]
type = "remap"
inputs = ["in"]
source = '''
. = parse_json!(.message)
# 写入的租户名
._tenant = "cnosdb"
# 写入的数据库名
._database = "public"
# 写入的表名
._table = "vector_log_test"
# 用户及密码
._user = "root"
._password = ""
'''
[sinks.cnosdb]
type = "vector"
inputs = ["json_transform"]
address = "127.0.0.1:8906"
需要注意的是,需要将tenant,database等参数配置到source中,如果不设置,会使用默认配置。
执行命令
vector --config log_vector.toml

也可以使用grafna查看CnosDB log数据
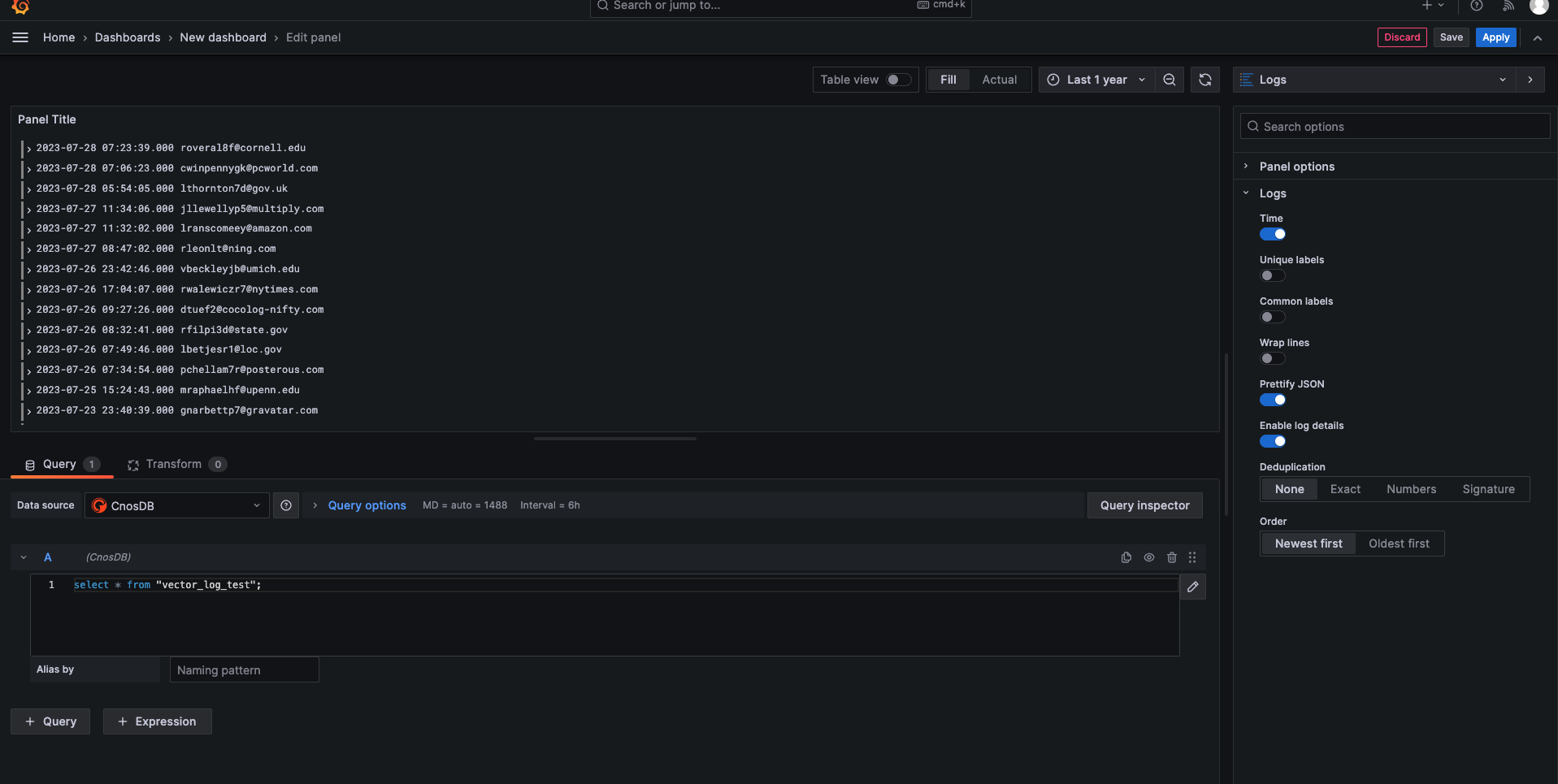
写入Vector Metric
示例收集Vector本身产生的metric
vector配置文件如下
[sources.example_metrics]
type = "internal_metrics"
[transforms.my_transform_id]
type = "remap"
inputs = [ "example_metrics" ]
source = """
# 与 Vector Log 类似,不同的是需要添加到 metric 的 tags 中,写入的 table 名为 metric 的 name 和 namespace(namespace.name),所以不需要指定 table 名
.tags._tenant = "cnosdb"
.tags._database = "public"
.tags._user = "root"
.tags._password = ""
"""
[sinks.cnosdb]
type = "vector"
inputs = ["my_transform_id"]
address = "127.0.0.1:8906"
需要注意的是,与日志类型配置文件不同,需要将参数如tenant,database等配置到.tags中。
执行命令
vector --config metric_vector.toml

使用client连接CnosDB查询
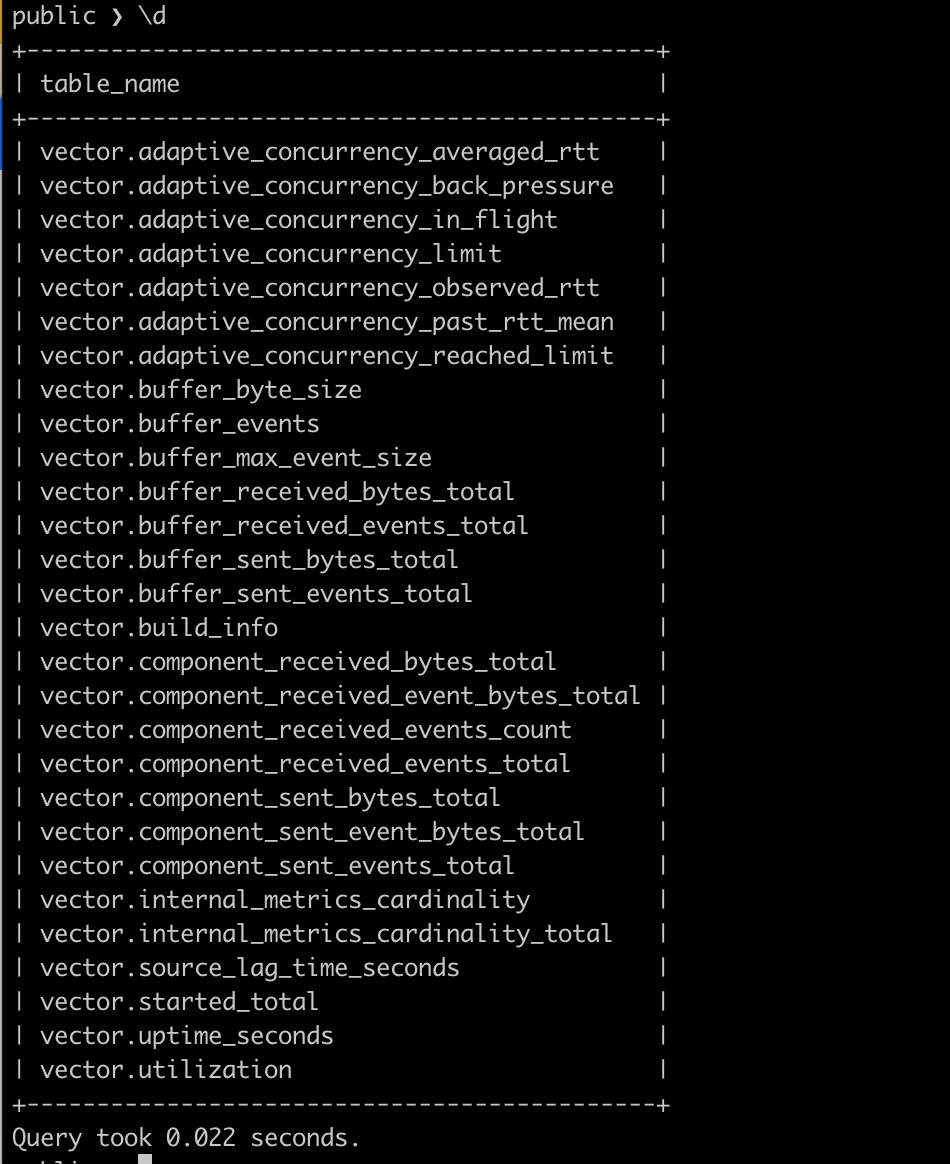
Grafana Loki
Promtail介绍
Promtail是一个用于收集日志并将其发送到Loki的日志收集代理。它是Grafana Loki项目的一部分,Grafana Loki是一个水平可扩展、高度可用的多租户日志聚合系统,专门用于存储和查询日志数据。Promtail主要负责从各种来源收集日志,将其处理并发送到Grafana Loki。
'{"streams": [{ "stream": { "instance": "host123", "job": "app42" }, "values": [ [ "0", "foo fizzbuzz bar" ] ] }]}'
CnosDB存储
CnosDB支持Promtail的写入接口是:ip:port/api/v1/es/_bulk?table=t1&log_type=loki,后两个参数不可省略。
启动流程
启动CnosDB:
./target/debug/cnosdb run --config config/config_8902.toml -M singleton启动Promtail:
promtail --config.file=promtail-local-config.yaml
clients:
- url: http://localhost:8902/api/v1/es/_bulk?table=t1&log_type=loki
basic_auth:
username: root
password:
Elasticsearch
CnosDB存储
写入接口是:ip:port/api/v1/es/_bulk?table=t1,后一个参数不可省略,对于es格式数据,CnosDB目前支持index和create两种。
Logstash介绍
Logstash是一个开源的数据收集引擎,能够动态地从各种来源收集数据,将其转换为期望的格式,并将其发送到指定的存储位置。它是Elastic Stack的一部分,与Elasticsearch和Kibana一起使用,用于集中化、分析和可视化数据。Logstash提供可自定义的存储端,在原来的数据流当中,Logstash会收集对应数据源的数据源,通过配置文件的filter以及处理流程之后,会输出到对应的存储端,通常会输出到Elasticsearch,通过正确的配置,可以输出到CnosDB当中,由CnosDB进行处理。

启动流程
启动CnosDB:
./target/debug/cnosdb run --config config/config_8902.toml -M singleton启动Promtail:
./bin/logstash -f logstash.conf
output {
elasticsearch {
hosts => ["http://localhost:8902/api/v1/es/"]
custom_headers => {
Authorization => "Basic cm9vdDo="
}
parameters => {
"table" => "t1"
}
}
}
Filebeat介绍
Filebeat是一个轻量级的日志收集处理工具(Agent),它是Elasticsearch堆栈的一部分,基于Golang语言编写。Filebeat旨在安装在各个节点上,根据配置读取对应位置的日志,并将其上报到指定的地方,如Elasticsearch或Logstash。Filebeat的设计注重资源占用少,适合在服务器上搜集日志,并且具有很高的可靠性,保证日志至少上报一次,同时考虑了日志搜集中可能出现的问题,例如日志断点续读、文件名更改、日志截断等。
启动流程
启动CnosDB:
./target/debug/cnosdb run --config config/config_8902.toml -M singleton启动Promtail:
./filebeat -c filebeat.yml
output.elasticsearch:
hosts: ["http://localhost:8902/api/v1/es/"]
allow_older_versions: true
username: "root"
password: ""
parameters:
table: "t1"
ndjson
{"date":"2024-03-27T02:51:11.687Z", "node_id":"1001", "operator_system":"linux", "msg":"test"}
{"date":"2024-03-28T02:51:11.688Z", "node_id":"2001", "operator_system":"linux", "msg":"test"}'
fluent-bit介绍
fluent-bit是一个轻量级的日志处理工具,专为资源受限的环境(如嵌入式系统、容器、边缘计算设备等)设计。它是Fluentd项目的子项目,提供了一套灵活的插件系统,用于收集、处理和传输日志数据。

启动流程
启动CnosDB:
./target/debug/cnosdb run --config config/config_8902.toml -M singleton启动Promtail:
fluent-bit -c fluent-bit.conf
[OUTPUT]
Name http
Match *
Host localhost
Port 8902
Format json_lines
URI /api/v1/es/_bulk?table=fluent&log_type=ndjson&time_column=date
http_User root
json_date_format iso8601